
多媒体复习大纲混讲
一章一章来。
第一章
多媒体的含义
(1)多媒体是信息交流和传播的媒体,从这个意义上说,多媒体和电视、报纸、杂志等媒体的功能是一样的。
(2)多媒体是人-机交互媒体﹐这里所指的“机”,主要是指计算机,(智能)手机或是由微处理器控制的其他终端设备。计算机的一个重要特性是“交互性”,使用它容易实现人-机交互功能,这是多媒体和模拟电视﹑报纸,杂志等传统媒体大不相同的地方。
(3)多媒体信息是以数字形式而不是以模拟信号形式存储和传输的。
(4)传播信息的媒体的种类很多,如文字,声音、电视图像,图形、图像、动画等。虽然融合任何两种或两种以上的媒体就可以称为多媒体,但通常认为多媒体中的连续媒体(声音和电视图像)是人-机互动的最自然的媒体。
媒体的含义
这是与多媒体比较对应的概念,只不过相较于多媒体,好背了一点:
一、指承载信息的物体,如手册、磁盘、光盘、磁带以及相关的播放设备等。二、是指承载信息的载体,
无损、有损压缩。可逆、不可逆
无损指的是数据压缩完之后再恢复,与原来的数据完全相同,所以叫无损,同时压缩和解压又是可逆的,所以这种编码方式也叫可逆编码。例如哈夫曼树
与之对应的是有损压缩和不可逆编码,指的是编码解码后与原来的数据不同了,但是编码得到的图像对人不产生影响。例如JPEG压缩
第二章
这个全都是要算的了
信息量的计算、哈夫曼树的计算、LZW编码和译码,这个后续整理一下
第三章
声音信号的频率与幅度,分别反映声音的什么现象
从这里到后续的各种话音编码基本就只考虑这两个参数了。
描述声音信号的两个基本参数是频率和幅度。信号的频率是指信号每秒钟变化的次数,用Hz表示。幅度则反应声音的响度。
什么是模拟信号和声音的采样、量化
模拟信号就是连续的信号,这里的连续是时间和幅度上的连续,也就是实际的声音,但是录音设备无法完全记录所有信息,其需要以固定的频率在每个时间点进行信号的采集,这个就是采样。幅度同样也是连续的,录音设备采集信号幅度并将其划分成若干段,这就是量化。经过了这两个操作得到的信号就是数字信号。量化的分隔相等的时候就是线性量化,否则是非线性量化。
而采样的频率也就决定了获取的信号的精度。其中著名的定理就是奈奎斯特采样定理。
采样频率的决定,奈奎斯特采样定理,量化精度反映什么
采样速率不应低于声音信号最高频率的两倍,这样就能把以数字表达的声音还原成原来的声音采样定律用公式表示为:f>=2f或T<=T/2其中,f,也称为奈奎斯特速率(Nyquist rate)。量化精度,反映度截声音波形幅度的精度。
亚音信号、语音信号、超声波信号、音频信号,它们的频率范围
0~20~20000~inf 300~3400
语音编码三种方式的含义
波形编码(waveform coding参数编码(parametric coding)和混合编码.
波形编码是用数字形式精确地表示模拟信号波形的编码方法
参数编码是使用发音器官生成语音信号的模型,对从语音信号中抽出语音的特征参数进行编码的方法,解码器根据模型参数重构语音信号。
混合编码是综合使用波形编码和声源编码技术,组合波形特性和语音特征参数的编码方法。
其中参数编码在不同地方的命名不同,也可以叫声源编码。
波形编码中最简单的就是PCM(脉冲编码调制),就是对模拟信号进行采样和量化得到数字信号
参数编码实际上就是找一堆音源来表示波形,最后使用这些音源的组合来形成波形。有点类似midi的原理
几种混账编码
PCM就是简单的量化和采样,前面提到了量化的线性和非线性,那么应用到PCM的量化中也就有了线性量化和非线性量化,分别是$\mu$律压扩和A律压扩。但是鉴于复习提纲没有提到,就不多说明了。
DM叫做增量调制,就是拿模拟信号的变化量来进行编码,属于一种预测编码。最拉跨的DM只需要对信号变化的极性(正或负)分别标志为0和1即可。也正是因此会出现下面的斜率过载和粒状噪声问题
为了解决DM的问题,就有人提出了ADM,自适应的增量调制,当多次出现增长的时候就提升量化阶,当基本不变的时候就减少量化阶
回到PCM,这个东西太拉了,所以就有人提出了APCM,自适应的PCM,这种方式根据输入信号的幅度进行量化阶的改变。
另一种PCM的改良是DPCM差分PCM(注意,不是增量PCM),其实利用了DM的思想,就是表示变化量而不是直接表示波形,但变化量的计算是通过实际信号值和预测值的差。
上述两种PCM改良的结合就有了ADPCM。详见后面的ADPCM介绍
斜率过载、粒状躁声
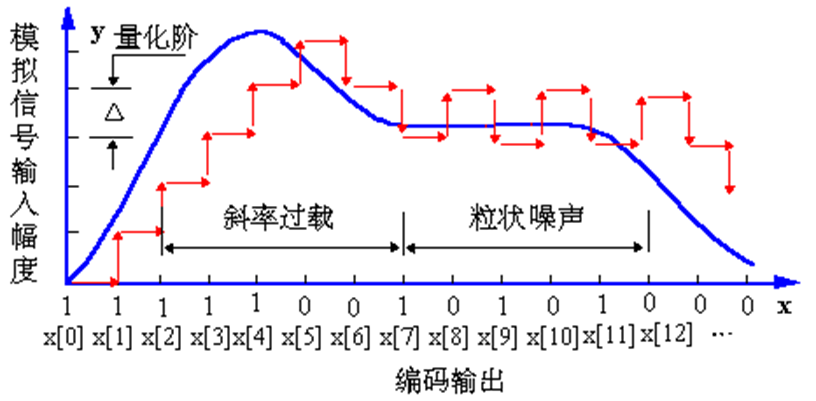
分成了两部分,由于DM表示的是信号的变化,那么当变化非常大的时候,这个编码就跟不上变化。后半部分是当波形基本不变化的时候,极性就会反复横跳,从而导致不断地出现0和1,导致噪声的出现。
什么是ADPCM
自适应差分脉冲编码调制,综合了APCM的自适应特性和DPCM的差分特性,是一种性能比较好的波形编码技术。它的核心思想是: 1、利用自适应的思想改变量化阶的大小,即使用小的最化阶(step-size)去编码小的差值,使用大的量化阶去编码大的差值;2、使用过去的样本值估算当前输入样本的预测值,使实际样本值和预测值之间的差值总是最小。
ADPCM的某个标准中用到了子带编码这个方式
子带编码
子带编码(Sub-B and Coding, SBC)的基本思想是:使用一组带通滤波器(band-passfilter,BPF)把输入声音信号的频带分成若干个连续的频段,每个频段称为子带。对每个子带的声音信号采用单独的编码方案去编码
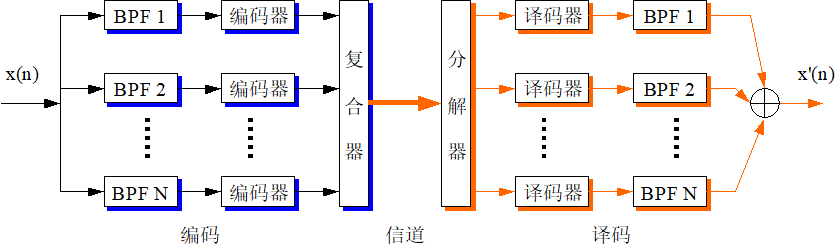
这样做的好处有二,1、对每个子带信号自适应控制,例如幅度高的自带就可以使用更高的量化幅度。2、根据子带信号在感觉上的重要性分配不同的位数,例如打电话的时候噪声往往是高频的,那么分配较少的位数给高频带。
MIDI的含义
MIDI是Musical Instrument Digital Interface的首写字母组合词,可译成“电子乐器数字接口”。用于在音乐合成器(music synthesizers)、乐器(musical instruments)和计算机之间相互连接并交换音乐信息的一种标准协议。
MIDI文件存放的是一系列指令(即命令的约定),它指示乐器即MIDI设备要做什么,怎么做,如演奏音符、加大音量、生成音响效果等。
第四章
RGB颜色空间、CMYK颜色空间,加色混色模型、减色混色模型,有源物体、无源物体8种颜色的不同表示
一个不发光波的物体称为无源物体,它的颜色由该物体吸收或者反射哪些光波决定,称为相减混色模型。
生活中,颜料的混合得到的图画是无源(不会自己发光)物体,对应生成的颜色就是相减色。
青色、品红、黄色为CMY模型,再加上黑色组成CMYK,通常用于打印机。
无源物体的8种颜色表示如下图(右图)

一个能发出光波的物体称为有源物体。
RGB色彩模型是有源的,由R、G、B三种基色来得到就是RGB颜色空间。
图像数据量的计算
图像大小*图像深度/8
(这里除8是将位转成字节,深度一般是位数表示)
真彩和伪彩色
真彩色(true color)是指每个像素的颜色值用红(R)绿(G)和蓝(B)表示的颜色。
伪彩色(pseudo color)是指每个像素的颜色不是由每个基色分量的数值直接决定的颜色,而是把像素值当作彩色查找表(Color Look-Up Table, CLUT)的表项人口地址,去查找显示
图像时使用的R、G,B值,用查找出的R、G,B值产生的彩色称为伪彩色。
矢量图和位图
矢量图是用一系列计算机指令描绘的图,如点、线、面、曲线、圆、矩形以及它们的组合。(理论上精度无限)
位图(bitmap)是用像素值阵列表示的图。
JPEG压缩计算
这个巨难,一会再说
第九章
两种电视制式的参数:帧频、场频、颜色模型
制式指的是电视在传送和接受信号时的编码标准或是格式标准。常见的就是NTSC和PAL
PAL:帧频25Hz、场频50Hz、颜色模型YUV
NTSC:帧频30Hz、场频60Hz、颜色模型YIQ
这里的PAL使用了YUV(亮度、色彩、饱和度)作为颜色模型,其开发的初衷就是为了兼容彩色和黑白电视(因为黑白电视只需要Y就可以显示了)
YIO的Y同样是亮度,但是I和Q分别表示两个色彩范围。
复合电视信号、分量电视信号、S-Video分离电视信号的区别
包含亮度信号、色差信号和所有定时信号的单一信号叫做复合电视信号(composite video signal),或者称为全电视信号。
分量电视信号(component video signal)是指每个基色分量作为独立的电视信号。每个基色既可以用RGB表示,也可以用亮度-色差表示,如YIQ,YUV。使用分量电视信号是表示颜色的最好方法,但需要比较宽的带宽和同步信号。
分离电视信号S-Video(Separated video-VHS)是亮度和色差分离的一种电视信号,是分量模拟电视信号和复合模拟电视信号的一种折中方案。
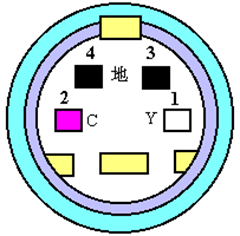
配合这张图好理解,复合电视信号就是所有的信息一条信号传输。上图就是一个S-Video分离电视新高,一条Y(亮度)一条C(色差)还有两个地线。
图像子采样的原理和依据、样本点数的计算,MPEG-1的子采样
这个是这节最重要的内容了属于是。子采样指色差的采样频率低于亮度的采样频率。那么做出这个决断的原因就是下面的原理
图像子采样是数字图像压缩技术中最简单的压缩技术。这种压缩技术的基本依据是人的视觉系统具有的两个特性, 一是人眼对色度信号的敏感程度比对亮度信号的敏感程度低,若把人眼刚刚能分辨出的黑白相间的条纹换成不同颜色的彩色条纹,眼睛就不再能分辨出单独的条纹,利用这个特性可以把图像中表达颜色的信号去掉一些而使人不易察觉;二是人眼对图像细节的分辨能力有一定的限度,利用这个特性可以把图像中的高频信号去掉而使人不易察觉。

如下图,前面就是亮度信息,中间是色度信息,显然,亮度信息也可以较为直观的反映出对颜色的认知。
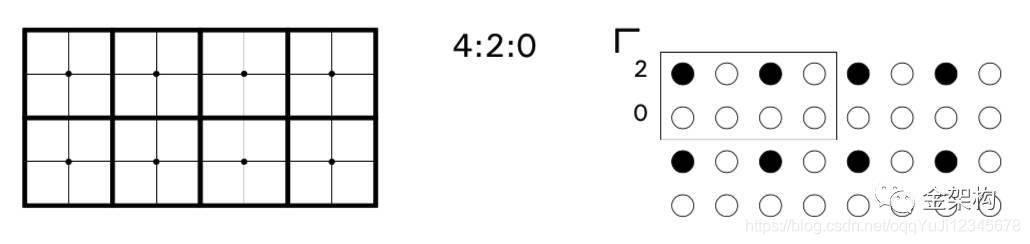
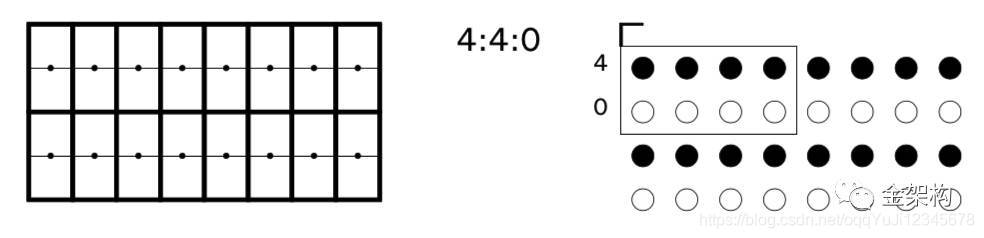
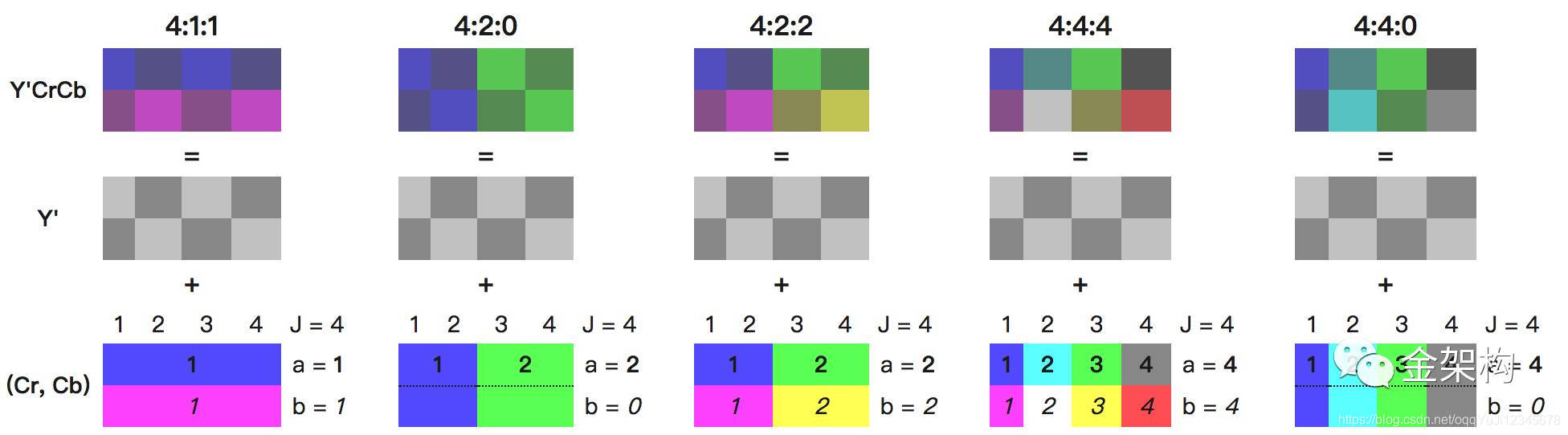
那么常见的子采样主要有:
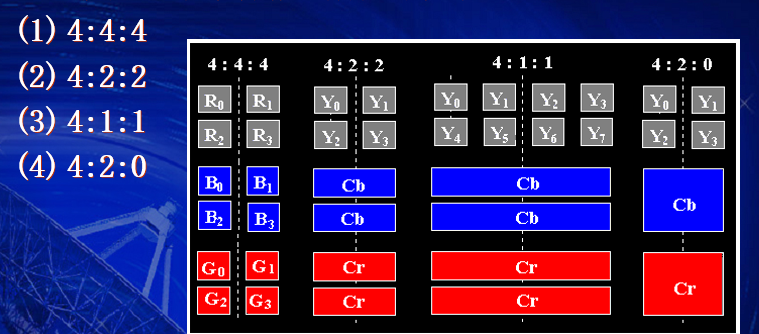
这种J:a :b的表示方式对应的参数:J也就是第一个位置,它表示水平采样点数目,通常我们以两行8个采样点为一个单位,每行4个采样点。第二个位置,也就是a,它表示4个采样点的第一行,色度样本的个数。第三个位置,也就是b,它表示4个采样点的第二行,色度样本的个数。上图的表示方式有点难以理解,首先康康下面的表示:



至于PPT和书上的图,实在是无法理解,建议直接背一下算了。
关于样本点数的计算,就是将三个数加起来除以4即为样本点数。例如4:4:4就是3个样本点数而4:1:1就是1.5个样本点数。根据使用范围不同,这里样本点数对应的位数也不同,在影视编辑上,由于色彩深度会使用10bit,而生活中通常使用8bit,对应样本精度就是样本点数*精度。例如4:4:4就是3*8=24位精度。关于扫描行的位置,也看一下:
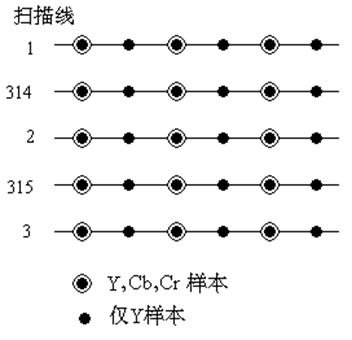

从上往下依次是4:4:4、4:2:2、4:1:1、4:2:0。
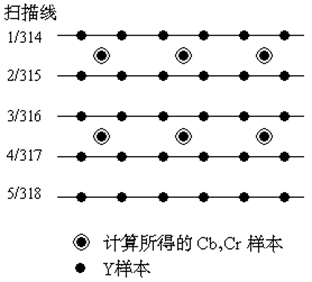
在完成了上面对子采样的介绍之后就可以康康MPEG-1的采样方式了:
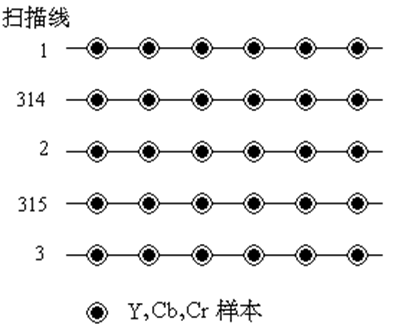
在水平方向的2个样本和垂直方向上的2个Y样本共4个样本有1个Cb样本和一个Cr样本,并且子采样在水平方向上有半个像素的偏移(图07-04-6,625扫描行系统)。如果每个分量的每个样本精度为8比特,在帧缓存中每个样本就需要12比特。

第十章
MPEG-1的应用、MPEG-2的应用
MPEG-1的应用:VCD但是很拉。MP3大量使用。
MPEG2-2:适用于广播质量的数字电视的编码和传送,被用于无线数字电视、DVB(Digital Video Broadcasting,数字视频广播)、数字卫星电视、DVD(Digital Video Disk,数字化视频光盘)等技术中。
MPEG-7的含义
MPEG-7标准被称为“多媒体内容描述接口”,为各类多媒体信息提供一种标准化的描述,这种描述将与内容本身有关,允许快速和有效地查询用户感兴趣的资料。它将扩展现有内容识别专用解决方案的有限能力,特别是它还包括了更多的数据类型。换言之,MPEG-7规定一个用于描述各种不同类型多媒体信息的描述符的标准集合
注意MPEG-7不是协议,而是标准集,用于检索不同媒体之间的关系。
第十一章
掩蔽效应、频域掩蔽、时域掩蔽
一种频率的声音阻碍听觉系统感受另一种频率的声音的现象称为掩蔽效应。
一个强纯音会掩蔽在其附近同时发声的弱纯音,这种特性称为频域掩蔽,也称同时掩蔽。
除了同时发出的声音之间有掩蔽现象之外,在时间上相邻的声音之间也有掩蔽现象,并且称为时域掩蔽。时域掩蔽又分为超前掩蔽(pre-masking)(5-20ms)和滞后掩蔽(post-masking)(50-200ms)。产生时域掩蔽的主要原因是人的大脑处理信息需要花费一定的时间。
什么是感知声音编码
感知声音编码主要利用听觉系统的两个基本特性:听觉阈值和听觉掩蔽。
心理声学模型中一个基本的概念就是听觉系统中存在一个听觉阈值电平,低于这个电平的声音信号就听不到,因此就可以把这部分信号去掉。
而听觉掩蔽则是指听觉阈值的大小随声音频率的改变而改变。
MPEG声音压缩的原理
MPEG声音有两种感知编码,第一种是感知子带编码,另一种 是杜比的AC-3。这里主要说感知子带编码:
除去心理声学模型,其实和子带编码看上去相同的。输入信号通过“滤波器组”进行滤波之后被分割成许多子带,每个子带信号对应一个“编码器”,然后根据心理声学模型对每个子带信号进行量化和编码,输出量化信息和经过编码的子带样本,最后通过“多路复合器”把每个子带的编码输出按照传输或者存储格式的要求复合成数据位流(bit stream)。解码过程与编码过程相反。
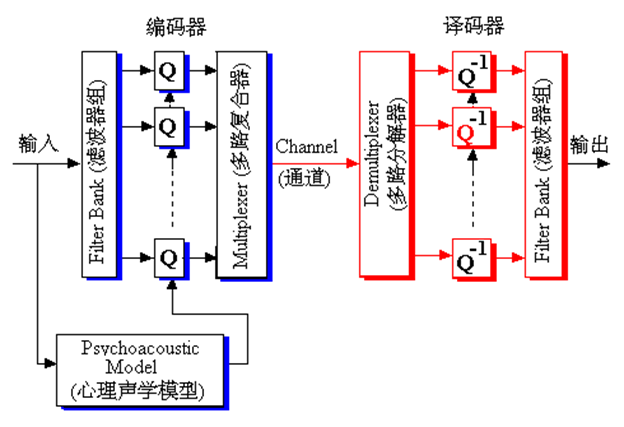
MPEG声音编码的三个层次,分别利用了哪些特性
MPEG声音输入为线性PCM信号,采样率为32kHz、44.1kHz或是48kHz,进行三层编码
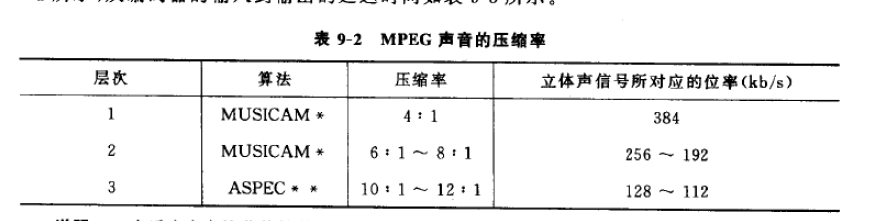
第1层使用频域掩蔽特性、等带宽子带,第2层使用频域掩蔽特性、等带宽子带和时间掩蔽特性,第3层使用频域掩蔽特性、时间掩蔽特性、立体声冗余和临界频带特性。(盲猜这个必考)
第十二章
各种冗余
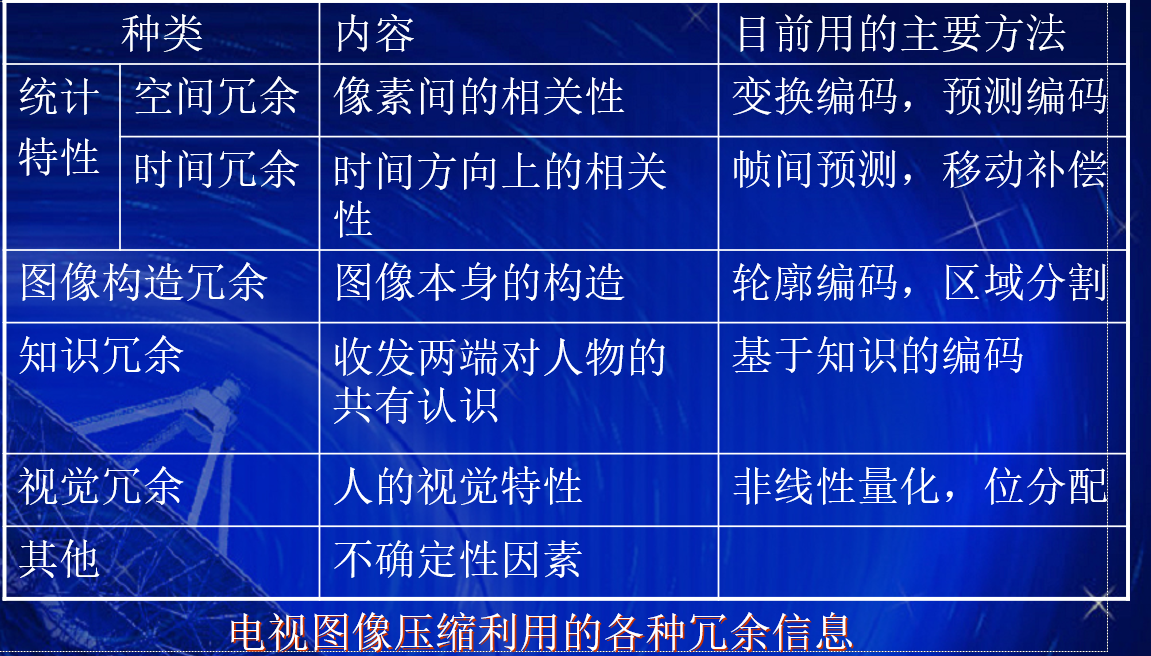
未压缩视频信号量的计算
水平像素 * 垂直像素 * 颜色位数 * 时间(s)/ 8
其中:PAL制:25帧/s
NTSC制:30帧/s
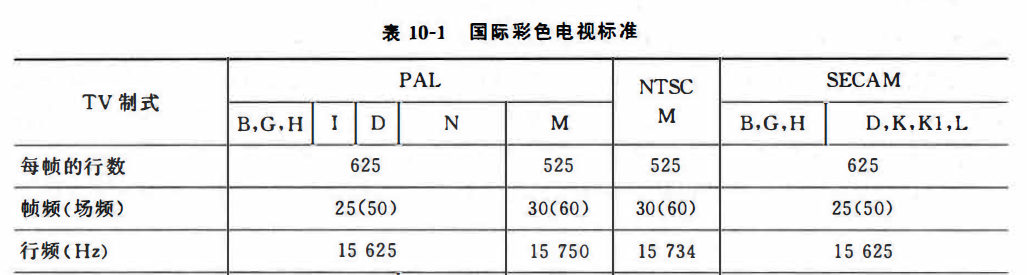
MPEG视频流中的三类视频图像,处理方法,压缩比的比较,图像出现的频率
MPEG专家组定义了三种图像:帧内图像I(intra),预测图像P(predicted )和双向预测图像B(bidirectionally interpolated ),典型的排列如图所示。这三种图像将采用三种不同的算法进行压缩。
帧内图像I不参照任何过去的或者将来的其他图像的帧,压缩编码采用类似JPEG压缩算法的帧内压缩。
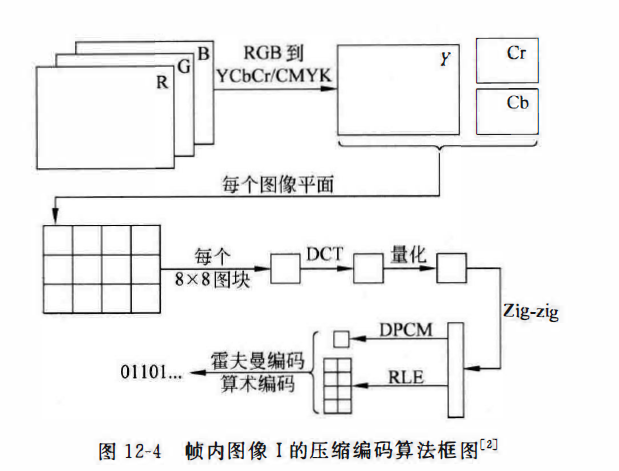
预测图像的编码也是以图像宏块(macroblock)为基本编码单元,一个宏块定义为I×J像素的图像块,一般取16×16:
假设编码宏块Mr1 是参考宏块MRJ 的最佳匹配块,它们的差值就是这两个宏块中相应的像素值之差。对所求得的差值进行彩色空间转换,然后使用4 : 1 : 1或4 : 2 : 0格式采样。对采样得到的Y、Cr和Cb分量值,仿照JPEG压缩算法对差值进行编码。此外,计算出的移动矢量也要进行DCT变换和霍夫曼编码。

P的编码实际上就是寻找最佳匹配图像宏块,来获得最佳移动矢量,移动矢量的计算可以使用MSE、MAD等等。搜索算法也可以使用各种,例如二位对数搜索法等
双向预测图像B的编码是对在它前后帧的像素值之差进行编码,计算方法与P类似
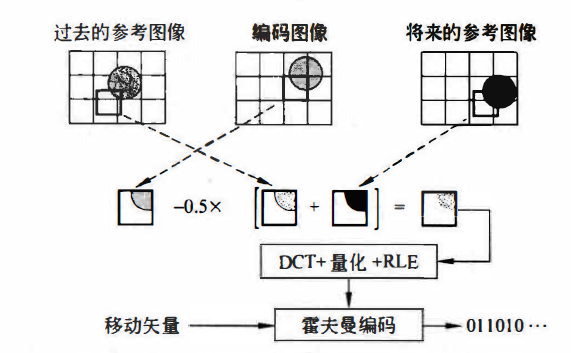
预测图像P使用两种类型的参数来表示:
Ø 一种参数是当前要编码的图像宏块与参考图像的宏块之间的差值
Ø 另一种参数是宏块的移动矢量、
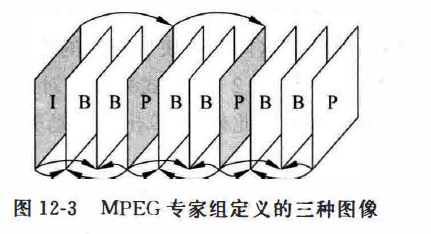
在MPEG-1中,B显然应该是压缩率最高的图像,同时是无法作为I和P的参考编码图像,所以B是不传播编码误差的。下表显示了三种图像类型的压缩比:

下图是三类图像的编排方式

在进行解码时,B需要使用P和I进行参考,但是,上图的编排方式显然不具备这样的条件,因此通常会进行顺序的一个调换:要注意下面的哪个是显示顺序哪个是传输顺序。

MPEG压缩时保存的值
宏观上的图像编排在上面的问题中提到了,这部分则是内部图像数据位的组织方式:
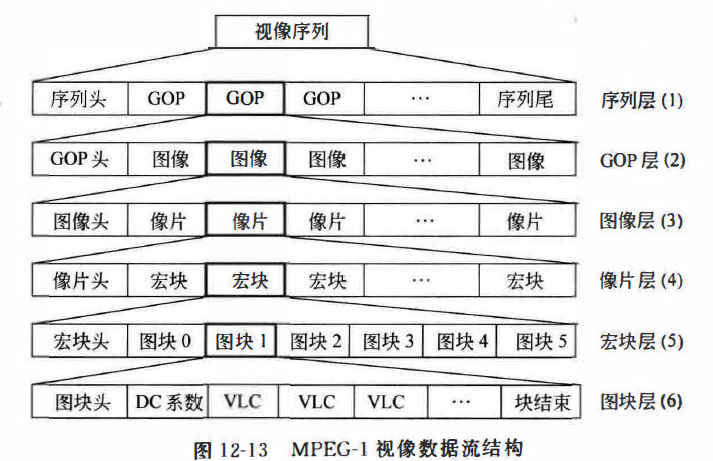
上面是MPEG1的数据流,有精力的还可以了解一下MPEG2的数据流。
MPEG的三种可变编码分别是什么,含义是什么
之所以提到MPEG2,就是因为MPEG的三种可变编码就是在MPEG2中提出的。可变编码的目的是为了适应各个方面的应用,从而可以保证在不同电视网络、互联网络中的图像质量不同,但是代价就是增加了编解码复杂性并降低了压缩效率。
那么MPEG2的三种可变编码分别是(实际上本来有五种,但是书上只是讲了三部分)
Ø 信噪比可变性SNR(Signal-to-Noise scalability):是指图像质量的折中,对于数据率比较低的解码器使用比较低的信噪比,而对数据率比较高的解码器则使用比较高的信噪比;
Ø 空间分辨率可变性(Spatial scalability):是指图像的空间分辨率的折中,对于低速率的接受器使用比较低的图像分辨率,而对于数据率比较高的接受器使用比较高的图像分辨率;
Ø 时间分辨率可变性(Temporal Scalability):是指图像在时间方向上分辨率的折中,与空间分辨率类似。
MPEG2和MPEG4的主要区别
因为两者的区别众说纷纭,所以从概念上来吧。MPEG4主要是可视对象编码标准,可以针对不同应用提供不同数据量,那么MPEG4核心就是视像对象编码和解码了。MPEG4可以理解成把图像的对象拆解之后合成(或者说,就是图层):
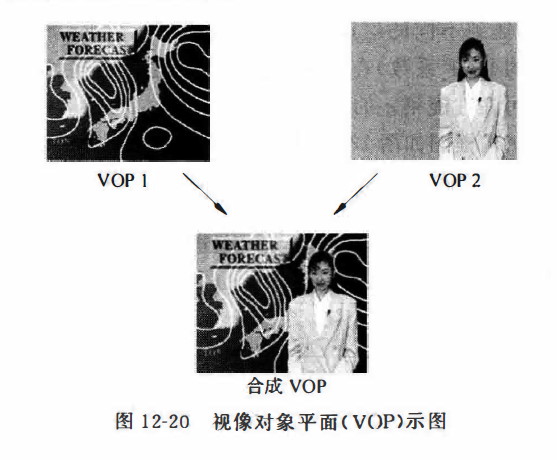
如果把MPEG1和2的帧视为VOP而画面视为纹理,那么MPEG1和2就可以认为是有纹理编码和移动编码组成。MPEG4认为从VOP中可以使用分割算法得到单独的物理对象,在空间上可以使用纹理表示,而在时间上可以以移动描述,所以VOP编码就是有形状编码、纹理编码和移动编码组成。
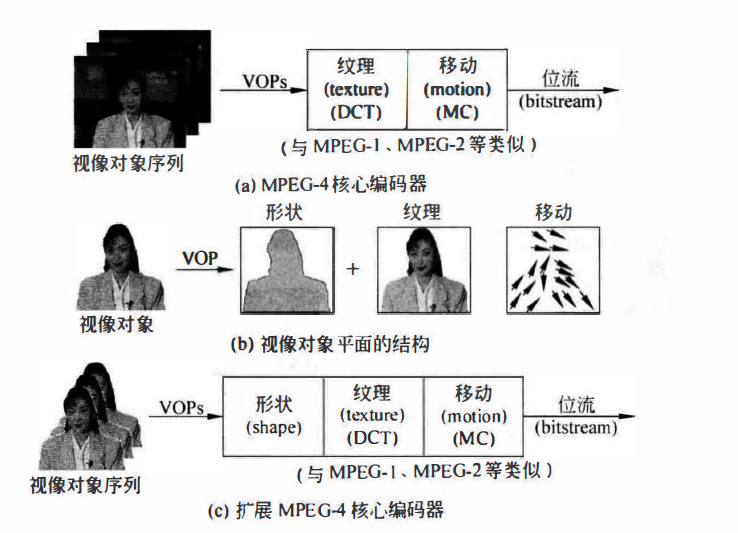
与MPEG1和2类似,也使用了IPB,但是相比1和2,还定义了两种精灵VOP。具体的编码方式和层次结构就没必要多说了,在这两个地方MPEG4与MPEG1和2区别较大,但是不难理解。
那么基于上述总结,MPEG4和MPEG2的区别主要可以从两个部分描述:组成和性能。
在性能上:MPEG2基于MPEG1标准改进,主要应用于DVD与数字电视视频的编码存储与传播,压缩率低于MPEG4,视频质量更高。
MPEG4主要用于压缩数字视频的编码存储与传播,交互处理功能强于MPEG2,理论上向下兼容MPEG1和MPEG2的编码信息。
在组成上:MPEG4使用了VOP而不是帧来表示图像,利用形状和纹理表示视像对象,在此基础上通过移动实现序列。即由视像编码、形状编码和纹理编码组成。只要将图像作为整体纹理处理就与帧的概念完全相同。但是由于组成上的不同导致了编码器和解码器乃至数据层次都有了一定的区别
第十五章
CD的光道与磁盘的磁道的结构
CD光道的结构与磁盘磁道的结构不同。磁盘的磁道是同心环,而CD的光道是螺旋形的。磁盘的磁道数目很多,而CD唱盘的物理光道只有一条,长度大约为5千米。磁盘的角速度恒定(磁盘的容量取决于最内侧的容量)而CD的线速度恒定
CD-ROM的凹坑与非凹坑,如何表示0和1
凹坑的边缘代表“1”(变化处),凹坑和非凹坑的平坦部分代表“0”(不变处)。
这里要注意几个区别。CD-ROM指的是只读CD,而CD-DA才是名正言顺的激光光盘。
CD-DA的采样频率与样本精度
- 1kHz 16位(PAL电视的场扫描为50Hz,NTSC电视的场扫描为60Hz, 所以取50和60的整数倍,选用44 lOOHz作为激光唱盘声音的采样标准。)
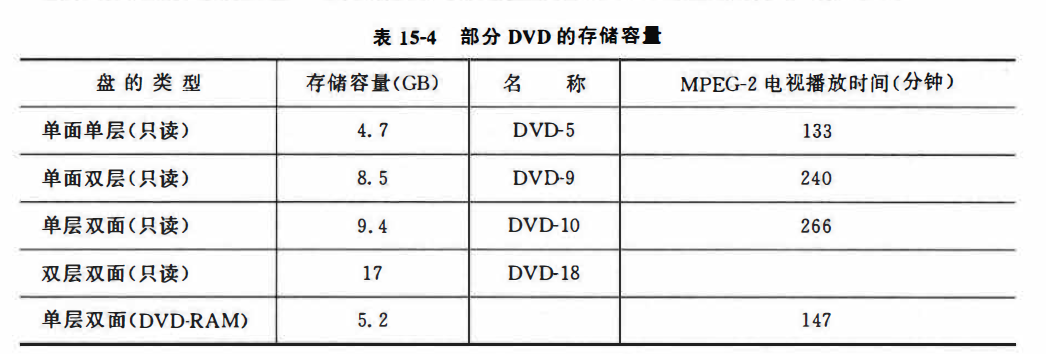
DVD存储容量的提高技术,各种类型DVD的存储容量
DVD指的是数字电视关盘,主要是与VCD做区别的。其提高存储容量的技术如下:
-
使用了波长较短的激光和数值孔径较大的光学读出头,使单片光盘的容量得到大幅度的提高。
-
加大光盘的数据记录区域
-
提高DVD 存储容盘的另一个重要措施是使用盘片的两个面来记录数据,以及在一个面上制作好几个记录层,这无疑会大大增加DVD 的容量
-
DVD 信号的调制方式和错误校正方法也做了相应的修正以适应高密度的需要。
对应的各种DVD的存储容量的表格如下:
第十六章
CD盘的物理格式和逻辑格式的含义
物理格式则规定数据如何放在光盘上,这些数据包括物理扇区的地址、数据的类型、数据块的大小、错误检测和校正码等。
逻辑格式实际上是文件格式的同义词,它规定如何把文件组织到光盘上以及指定文件在光盘上的物理位置,包括文件的目录结构、文件大小以及所需盘片数目等事项。
CD-DA:一个扇区多少帧,每帧多少声音数据,每秒多少扇区
答案:98帧组成一个扇区(sector)。 1帧存放24字节的声音数据,75 扇区/秒
推导过程:激光唱盘上声音数据的采样频率为44. 1kHz, 每次对左右声音通道各取一个16位的样本,因此1秒钟的声音数据率就为:
44 .1*l000*2*(16/8)=176 400字节/秒
由于1帧存放24字节的声音数据,所以1秒钟所需要的帧数为:
176 400/24=7350帧/秒
98帧构成1节,也可以说成1个扇区,所以1秒钟所需要的扇区数为:
7350/98=75 扇区/秒
CD-ROM Mode1存放什么

课本对这每部分的介绍相当弱智,所以不花时间说明了。
CD-ROM Mode2存放什么
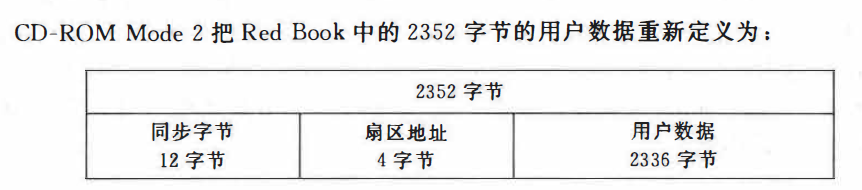
要注意的一点是在Mode2的扇区地址中,需要位方式字节域的值设置为02
CD-ROM/XA增加了哪些光道,有什么优点
CD的标准由一系列红皮书、黄皮书等记载。其中CD-DA就记载在红皮书中,而CD-ROM记载在黄皮书中。CD-ROM/XA 光道连同之前红皮书和黄皮书的定义就一共有4个光道:
(1)CD-DA: 用于存储声音数据; (2)CD-ROM Mode 1: 用于存储计算机数据; (3)CD-ROM Mode 2: 用于存储压缩的声音数据、静态图像或电视数据; (4)CD-ROM Mode 2,XA 格式,用 于存放计算机数据、压缩的声音数据、静态图像或电视图像数据。这个就是新增的光道。
除此之外也对扇区做了扩展,定义了Form1和Form2,全称详见书390页。Form1用于存储计算机数据,而Form2则允许各种多媒体数据存储在同一条光道上,所以声音、图像等就可以按照Form2格式存储。同一光道上的计算机数据和多媒体数据分别以Form1和Form2存储。
关于CD-ROM/XA的相关概念真是少之又少让人觉得可能是老师在搞我们。
由于CD-ROM/XA是对黄皮书的小幅度扩充,引入了一定的CD-I的特性其中。优点如下:
- 就对于增加了光道这一点,其开发的Mode2,XA,引进了CD-I的概念,运行计算机数据、压缩的声音数据和图像数据交错放在同一光道
- CD-ROM/XA中的声音使用了ADPCM来进行压缩,并定义level B和level C两个等级,使得腾出空间存放其他相关信息。
ISO 9660标准的含义
前面提到了CD-ROM是在黄皮书里面的。那么ISO 9660实际是定义CD-ROM的文件系统的内容,因此该标准也定义在黄皮书中。
ISO 9660是ISO发布的CD-ROM文件系统标准,定义卷描述符(Volume Descriptor)、目录结构(Directory Structures)和路径表(Path Table)三种类型的数据结构,以支持不同的操作系统,如UNIX、 Windows和 Mac OS。
CD-ROM逻辑扇区的大小,单倍速光驱的速率
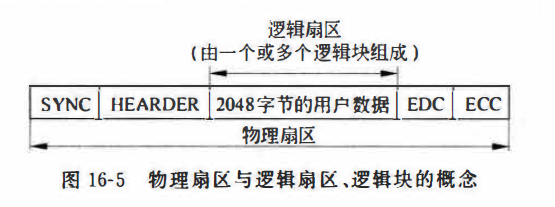
2048字节 150KB/S
CD-ROM文件系统的组成
文件系统指的是存储媒体上组织数据的方法。即逻辑结构。主要由两个部分组成:
- 定义一套描述整片CD-ROM盘所含信息的结构,称为卷结构(Volume Structure)
- 定义一套描述和配置文件的结构,称为“文件结构(File Structure)”,其核心为文件的目录结构
由于下面会说明目录结构,这里就提一下卷结构,CD-ROM中存数据的地方就是卷空间,其中0~15LSN为系统区,而16及以后为数据区,卷描述、文件目录、路径表、数据等。
每卷数据区的开头由2048字节组成。
CD-ROM目录结构
隐式分层目录结构。这是由CD-ROM只读的导致的,因为没必要对目录进行增加和删除。CD-ROM对目录结构自己做了规定:目录文件由可变长目录记录组成。
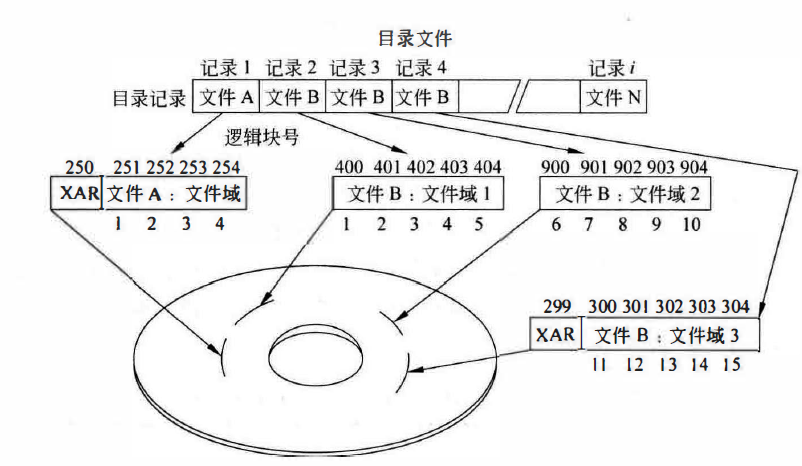
除了自定的一堆结构以外,如果文件有附加信息,可以放在XAR中,从而减小目录记录的大小。如果一个文件有多个文件域,可能出现的问题就是XAR信息不同步,因此只认定最后的XAR记录有效。
VCD标准的含义
VCD,影音光碟(Video Compact Disc;VCD),是一种在光碟(Compact Disk)上存储视频信息的标准。属于数字光盘的白皮书标准。盘上的声音和电视图像都是以数字的形式表示的。
第十七章
CRC计算和检错原理
RS编码含义
(n,k)RS编码
计算
熵的计算
熵的计算公式为:$H(X)=E[-\log{p_i}]=-\sum_{i=1}^np_i\log p_i$
这个不难理解,详见作业3.4
哈夫曼编码
这个学臭了都,注意下平均码长的计算:$\sum_{i=0}^np(i)len(i)$
LZW编码
不难理解但是容易出纰漏。LAW属于字典编码。
LZW的目的是获取一个LZW词典,这种编码方式通过这个LZW字典实现输入和输出的转换。其中输入是字符流(8位ASCII字符串),输出是码字流。
为了获取这个词典,LZW使用的是贪婪分析方法。每次检查来自字符流的字符串,从中分解出已经识别的最长的字符串,并用一致的前缀加上 下一个输入字符来形成一个扩展字符,形成新的键值对。
LZW词典的前几个词典是字符串流中可能出现的所有字符。在进行LZW编码的时候需要的记录的有:步骤、位置、词典和输出。如下图:

首先从A开始,A+B得到一个串,由于AB没有出现在词典里,所以添加进去,同时AB是以A开头的,所以对应的输出就是A的码字。接下来是A之后的B+B同样没有出现过,和上面的操作相同。BA同。到第4个位置A时,A+B显然已经出现过了,所以继续加得到ABA添加到词典里并记录AB的码字。之后从第六个位置开始A+B+A显然出现过,所以再加一位ABAC添加到词典并记录ABA的码字。
所以LZW的流程实际上是使用贪心找到第一个新出现的字符串,以方便下次使用。
通过上面的操作,得到的输出就是(1)(2)(2)(4)(7)(3)
译码就没有难度了,直接根据字典查即可。
接下来在康康作业题目:ababcbababaaaaaaa…的LZW编码
首先把单独的添加到字典里,即a,b,c添加进去,接下来ab没有出现过,所以ab添加进去
| 步骤 | 位置 | 词典(流) | 词典(字符) | 输出 |
|---|---|---|---|---|
| (1) | a | |||
| (2) | b | |||
| (3) | c | |||
| 1 | 1 | (4) | ab | (1) |
| 2 | 2 | (5) | ba | (2) |
| 3 | 3 | (6) | abc | (4) |
| 4 | 5 | (7) | cb | (3) |
| 5 | 6 | (8) | bab | (5) |
| 6 | 8 | (9) | baba | (8) |
| 7 | 11 | (10) | aa | (1) |
| 8 | 13 | (11) | aaa | (10) |
| 9 | 16 | (12) | aaaa | (11) |
好吧,我摆烂了,我并不想写位置。但是真正理解LZW的运作原理之后这个东西就很容易了。
接下来是解码:把输出对应的一个个查出来即可:a(1)b(2)ab(4)c(3)ba(5)bab(8)a(1)aa(10)aaa(11)
JPEG压缩
JPEG压缩有六个步骤:DCT变换、量化、Z形编码、DPCM编码、RLE编码和熵编码(其中只有量化有损)
拿两道作业题试手。要注意的一点是,考试不会拿图像数据直接让你硬压,因为压缩的DCT变换没有计算机是几乎算不出来的,所以一半给出的就是图像分量的系数和前一个图像的DC系数。(但是在进行DCT之前有时候会进行一些+-像素值的操作,例如书中的例子就是在像素加了128之后进行的DCT,因此在回复的时候)
第一题:确实给出了FDCT后的系数和DC系数
第一步是量化,直接每位除量化表(具体量化表的选择,如果没有特殊说明,查亮度,如果题目说明了图像的信息就查对应的量化表),之后进行四舍五入:
所以量化之后得到的就是:剩余的0就不写了
| 13 | 0 | 2 | 0 | 0 | 0 | 0 | 0 |
|---|---|---|---|---|---|---|---|
| -2 | -2 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | -1 | 0 | 0 | 0 | 0 | 0 | 0 |
| -1 | 0 | ||||||
| 0 | |||||||
上面的表中,最左上角的元素是直流DC系数,而其它的63个值都是交流分量。得到上面的表格之后使用zigzag进行编码,有点像化学电子数变化的方式:
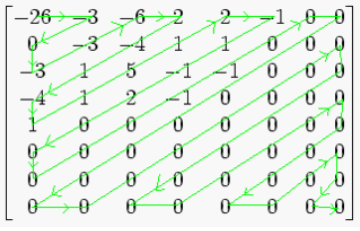
所以得到的编码就是13 0 -2 1 -2 2 0 0 -1 -1 0 0 0 …()这里的13是DC系数而其余的都是AC系数,因此处理方式不对。
接下来要获取中间符号,对于DC系数13,由于前一个图像块的DC系数是8,由于DC系数是需要求差值的,所以得到的差值为5且对应的码长为3。所以中间符号为(3,5)
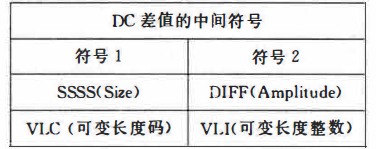
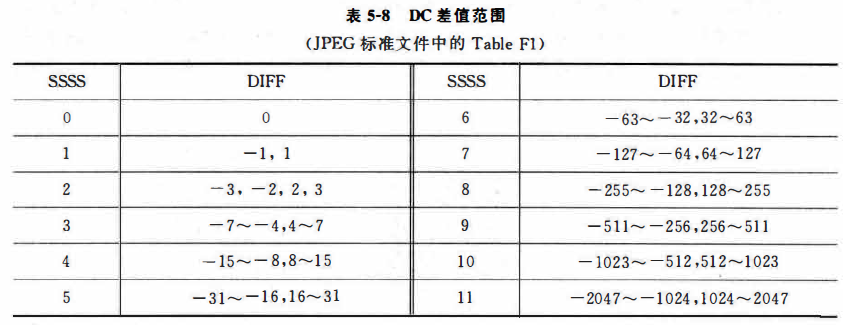
接下来是AC系数,这个不需要进行差分,且求取过程不算很难
接下来要对AC系数进行RLE压缩,得到的应该是(1,-2)(0,1)(0,-2)(0,2)(2,-1)(0,-1)(0,0)。不难理解,这里括号的两个数一个表示数字前面0的个数,一个就是当前值(AC系数),最后的(0,0)表示EOB。
AC系数同样是需要码长的,但是与DC的不同:
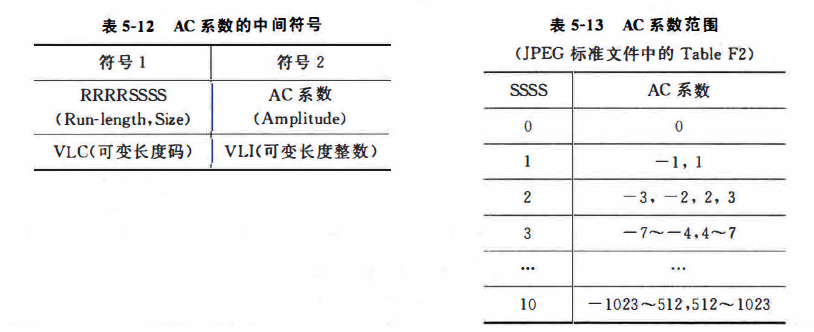
所以AC系数的中间符号为(RLE/SSSS,AC系数)
所以完整的中间符号应该是(3,5)(1/2,-2)(0/1,1)(0/2,-2)(0/2,2)(2/1,-1)(0/1,-1)EOB
理解到这一步,离结束就差编码了。对上面的中间符号应该一一对应编码。对于DC的中间符号,前部分用下图中的两种之一(仍然根据题目条件)表示:后面的部分则是补码,即5的补码101。所以DC中间符号就是100 101。
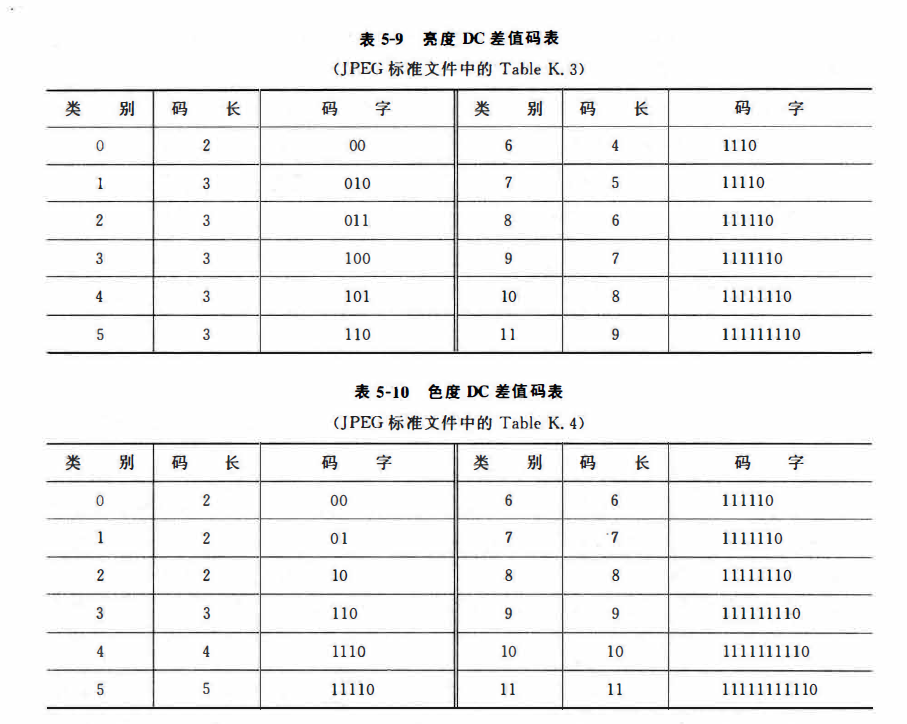
之后是蛋疼的AC中间符号编码,
对于(1/2,-2)而言,要先查这两个表(实际上是需要求哈夫曼树的但是实际上直接查表也行),不难看出,下面的两个码表都只给了R/S。但是对于AC系数,前面的表5-13已经给出了AC系数范围,所以我们需要使用两位码长表示-2,如果是按照书上的直接补码,实际是有点问题(书就是个JB,直接复制DC的DIFF概念都不改一下)。太sb了!
所以自己总结一下,就目前看到的数字无论是-6、-8、-2、-1,-3,都是直接对绝对值求反码即可,所以-6为110的反码001,-8为0111,-2为01,-1为0,-3为00,这样还同时满足了DIFF符号位的条件。
所以对这个中间符号继续搞(1/2,-2)(0/1,1)(0/2,-2)(0/2,2)(2/1,-1)(0/1,-1),就有
11011,01;00,1;01,01;01,10;11100,0;00,0;
加上前面的DC编码和最后的EOB(1010),就能得到最终结果:
100 101 11011 01 00 1 01 01 01 10 11100 0 00 0 1010
剩下的就很简单了,上面编码的长度为37,而原图的大小是8*8个像素,且每个像素深度为8位,所以压缩比就是8*8*8/37=13.84
压缩率=数据率=即每像素bit数,压缩率就是37/(8*8)=0.579 (这点是老师说的,感觉有点问题)
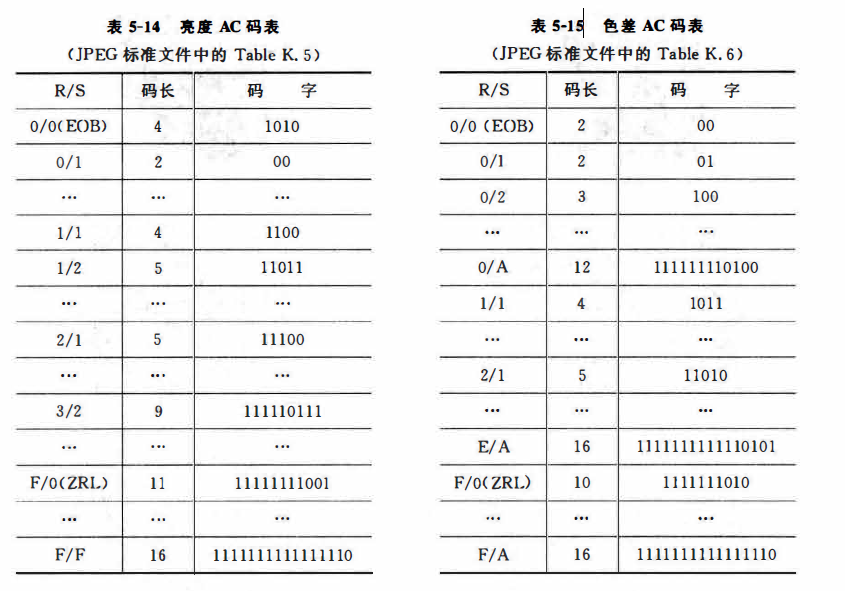
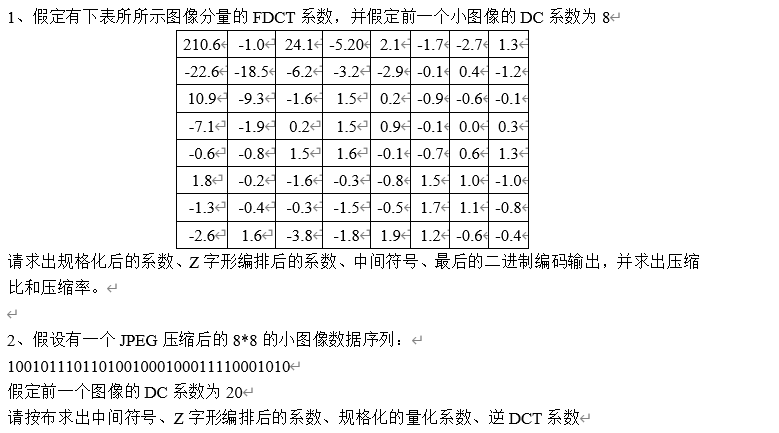
第二题是进行解码的,那么对于数据序列,有必要分成每个部分来进行中间符号的获取。
100101|11011,01|00,1|00,0|100,011|1100,0|1010
前面的部分是DC系数,所以先查DC码表,可以看到100是亮度DC差值码表中码长为3的码字。DC系数的另一部分是与前一部分的差值,由于知道了码长为3,所以接下来的三位101即为对应的差值,即为5。题目中提到上一个图像的DC系数为20,所以这里的值就是20+5=25
最后四位必然是1010
接下来是枯燥的查表过程,由于AC系数是基于哈夫曼编码的,因此必然不会出现重复,同时也可以根据前后的位数来判断自己是否中间计算错误,总之,很难查错,11011 和 01对应的(1/2,-2),00和1对应的是(0/2,-1),00和0对应的是(0/1,-1),100和011对应的是(0/3,-4),1100和0对应的是(1/1,-1)
所以结合起来,中间符号就是(3,5)(1/2,-2)(0/2,-1)(0/1,-1)(0/3,-4)(1/1,-1)EOB
接下来是恢复获取Z形编码,由于前一个图像块的DC系数为20,所以这块的Z形编码就是25,0,-2,-1,-1,-4,0,-1,0,0,…
所以原图就是(其余的0就不写了)
| 25 | 0 | -4 | 0 | 0 | |||
|---|---|---|---|---|---|---|---|
| -2 | -1 | -1 | 0 | ||||
| -1 | 0 | 0 | |||||
| 0 | 0 | ||||||
| 0 | |||||||
最后求逆DCT系数就是按位称亮度量化表上的值,所以可以得到:
| 400 | 0 | -40 | 0 | 0 | |||
|---|---|---|---|---|---|---|---|
| -24 | -12 | -14 | 0 | ||||
| -14 | 0 | 0 | |||||
| 0 | 0 | ||||||
| 0 | |||||||
这个就是最终结果了。
CRC循环冗余校验
原理如下:

拿作业的例题康康。假设生成多项式G(x)为x^16 +x^12 +x^5+1,请求信息4D6F746F的CRC校验码。
那首先把生成多项式转成十六进制(注意,不要傻傻的转成二进制然后计算),这个生成多项式对应的二进制是1|0001|0000|0010|0001对应的十六进制就是11021H,由于这里的生成多项式是17位的,那么信息后面应该加上17-1即16位的校验码,所以原信息就是4D6F746F0000。接下来就做除法,做除法的时候不是正常的减法而是逻辑减,如果存在计算困难的话可以参考这个表格,所以计算的结果如下:

最后将B994替换掉原有的冗余位。
RS编码和(n,k)RS编码
RS编码简单来说,纠错能力很强,可以同时纠正多个码元错误。
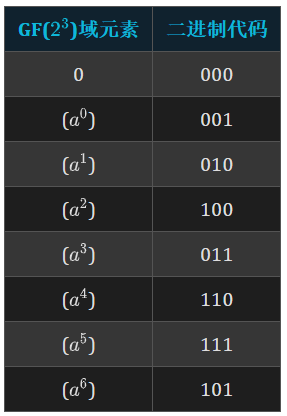
在介绍RS编码之前,需要先知道GF(伽罗华域),GF($2^m$)中有$2^m$个元素,其中每个元素都可以使用$a^0,a^1,…,a^{m-1}$表示。到这里其实和二进制一样的。
我们知道3位二进制数中2就表示010,3就表示011,这样。但是对于GF,稍微有点不同,GF的元素计算使用这个公式:$mod (\frac{x^{2m-1}+1}{P(x)})=0$
假设要构造一个GF($2^3$)域,定以本源多项式$P(x)=x^3+x+1$若定义a为P(x)=0的根,那么这个域中元素的计算:

从多项式的表现上看,就是阶数达到某个阈值之后会平移。那么我们也可以把这些元素转为二进制:
那RS码的思想就是选择一个合适的生成多项式,使得对每个信息字段计算得到的码字多项式都是生成多项式的倍数。,如果接收到的码字多项式除以生成多项式余数不为0,就说明有问题。就这点而言,其实和CRC思想挺像的。
另一个要提的是GF域的运算规则。加减法都是位异或运算,惩罚是相乘后阶数取模,除法类似:
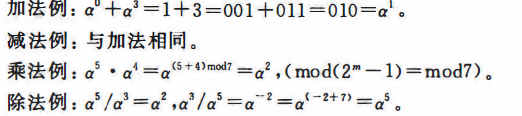
这些是步进RS编码的第一步,因为接下来就是RS码的表示方式了。

这一坨东西就是RS码的表示方式了,RS码用RS(n,k)表示,其中各个符号的含义如上。那么只要我们知道了n和k,理论上就能知道校验码符号数、纠正和检测到的错误符号数。