核心主要参考上述文章,感觉写的非常详细非常好,可惜是一个训练的流程,对于很多就业场景其实无法适应,但是适合短平快的学习。

Overview
对于大模型的训练,其中主要卡在显存占用、计算效率和通讯代价三部分,在实际场景下,往往不会有三者同时最优解,因此绝大多数情况需要详细的均衡以达到更好的效果。
模型的显存占用通常分为:模型权重、模型梯度、优化器状态、激活值这四部分,这就不用多说了。一般来说我们不按照详细的计算流程,而是通过模型参数量简化大致的显存计算。
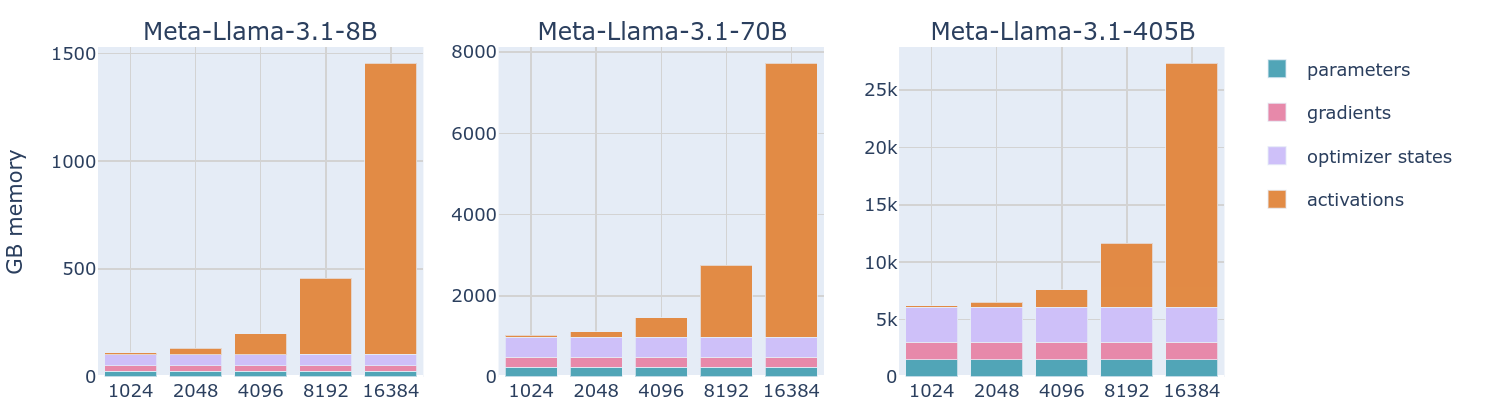
但是无论如何,相较于模型参数量,token长度和batch大小或许才是影响显存占用的主要参数。但是这种占用确实不应该,因此相较于完全存储激活值,一个合理的实现其实是**重新计算(re-computation)**部分激活值。
通过选择性的计算部分激活值,可以将原本大量的显存占用降低到极低,使得大batch的训练成为可能。
然而尽管通过选择部分activation值进行重计算可以大幅度减少显存占用,但是问题在于无论如何这个激活值和seq以及batch成正比,因此在有些情况下还是会遇到瓶颈,这时候的另一个解决方案就是梯度累计。
梯度积累的原理倒是很简单,多进行几个step的前向传播和反向传播,之后进行优化操作,因此可以step/N的batch下通过N次积累实现类似的效果,但是问题是这种操作会在一定程度上增加计算的时间(batch size理论上下降了N倍)
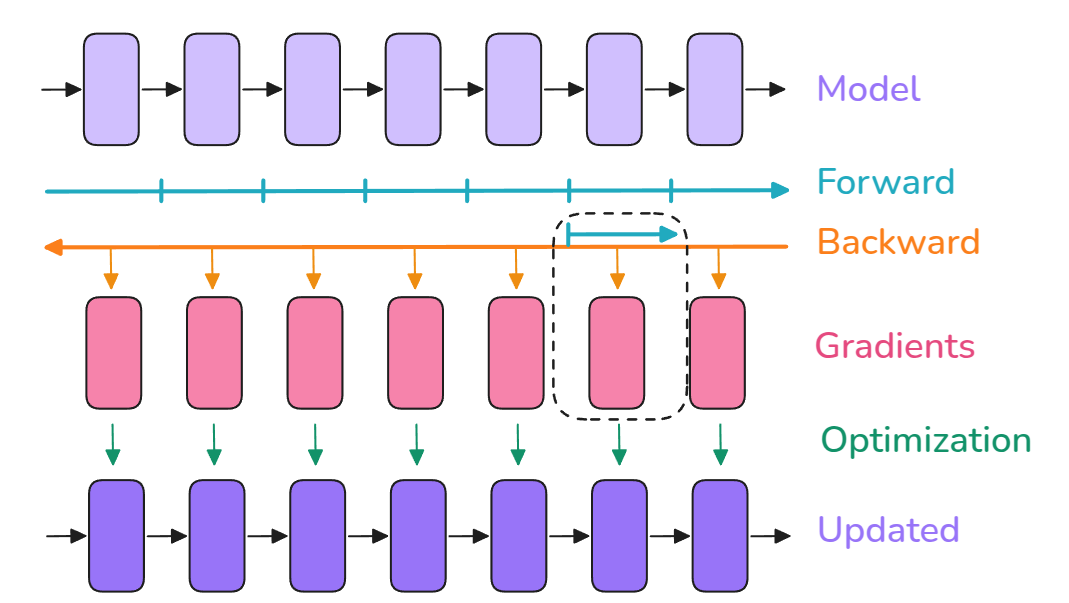
然而,当出现在多卡架构下时,一个有效的手段就是每个显卡跑一个相同的模型并使用相同的梯度积累手段,只不过在完成N/2的积累之后两两gather一下以实现同样的梯度积累效果,提高计算的速度。所以接下来,进入多卡的训练阶段:
数据并行DP
前面提到了梯度积累的手段,在多卡架构下进行上述的训练手段实际上就是一种数据并行方法,将数据分成两份进行并行计算。从各个角度来看,这都是一个免费的操作,真的吗?
想必很快就会遇到的一个巨大问题就是,如果一个模型的参数量无法被一张卡容纳,那自然会带来很多的问题,但是在讨论更加复杂的情况之前,可以先继续详细理解一下DP的相关算法和概念。

上图是一个三卡的DP的一个实例,很显然,非常舒适,但是上图其实画的不对,对于这种气泡图,通常是需要把每个设备的计算都得画出来的。但是先不看这一点了。因为要解决的气泡都是在计算阶段的,看到这个巨大的AllReduce操作,如果能在通信的时候也计算就再好不过了。
第一个优化手段倒也很简单,由于反向传播确实是只有一次的递进过程,因此最好的操作就是在传播期间就进行梯度的Reduce操作:

为了实现原理,这个playbook甚至提供了代码:
def register_backward_hook(self, hook):
"""
Registers a backward hook for all parameters of the model that
require gradients.
"""
for p in self.module.parameters():
if p.requires_grad is True:
p.register_post_accumulate_grad_hook(hook)
相较于只是对梯度的碎片进行reduce操作产生较大的gap,另一种有效的手段就是把梯度bucketing之后再发送:

相对来说的实现也会复杂很多。上述的实现算是一种潦草的版本,好在之后进行的就是工程上的优化了,比如如何实现同步,如何利用缓存加速存取通讯,都是值得研究的地方,但是太涉及架构的可以后续继续说。
然而问题来了,现在确实有个大模型,但是不那么大以至于可以放在一张80GB的显卡中,提供512张这样的显卡节点,那么较好的手段自然还是梯度积累,通过积累1个step,每个设备合起来直接积累了512Batchsize的梯度,从而实现了较好的存储优化,但是问题是:随着设备数量的增加,不可避免的是,通讯延迟会变成环延迟,即数据给到每个设备的时间(走一轮):
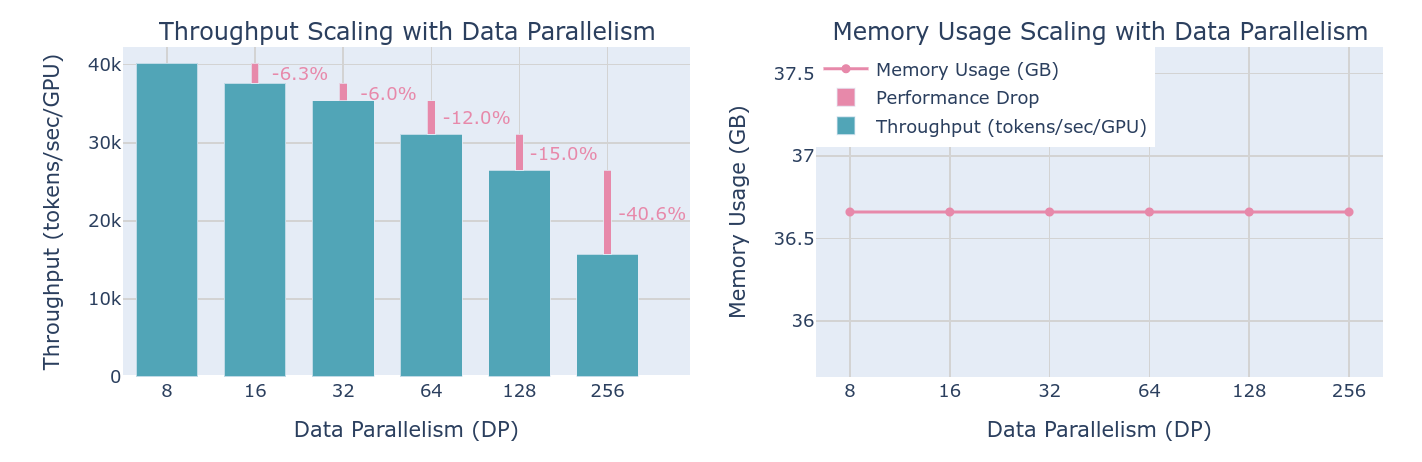
虽然每个设备上的内存不变,但是吞吐量会线性减小。而且对于更大一点的模型,实际上这种手段就完全没用了。即便如此,还是有一些手段在DP的基础上进行了优化,这就是比较出名的ZeRO(Zero Redundancy Optimizer)
免费的午餐:ZeRO1~3
ZeRO目前主要有三个版本:
- ZeRO-1: optimizer state partitioning
- ZeRO-2: optimizer state + gradient partitioning
- ZeRO-3 (also called FSDP for “Fully-Sharded Data Parallelism”): optimizer state + gradient + parameter partitioning

从整体的架构来看的话就张这个样子,其实已经足够清晰了。
在原生的DP中,需要每个设备都拥有所有的数据并保存完整的梯度。因此对于ZeRO-1而言:
- 相同的前向传播,但是每个设备只有microbatch。相同的反向传播。
- 对梯度做all_gather得到所有设备上的梯度和
- 每个设备对自己的一部分参数做优化器状态的保存并做优化
- 所有设备做all_gather操作
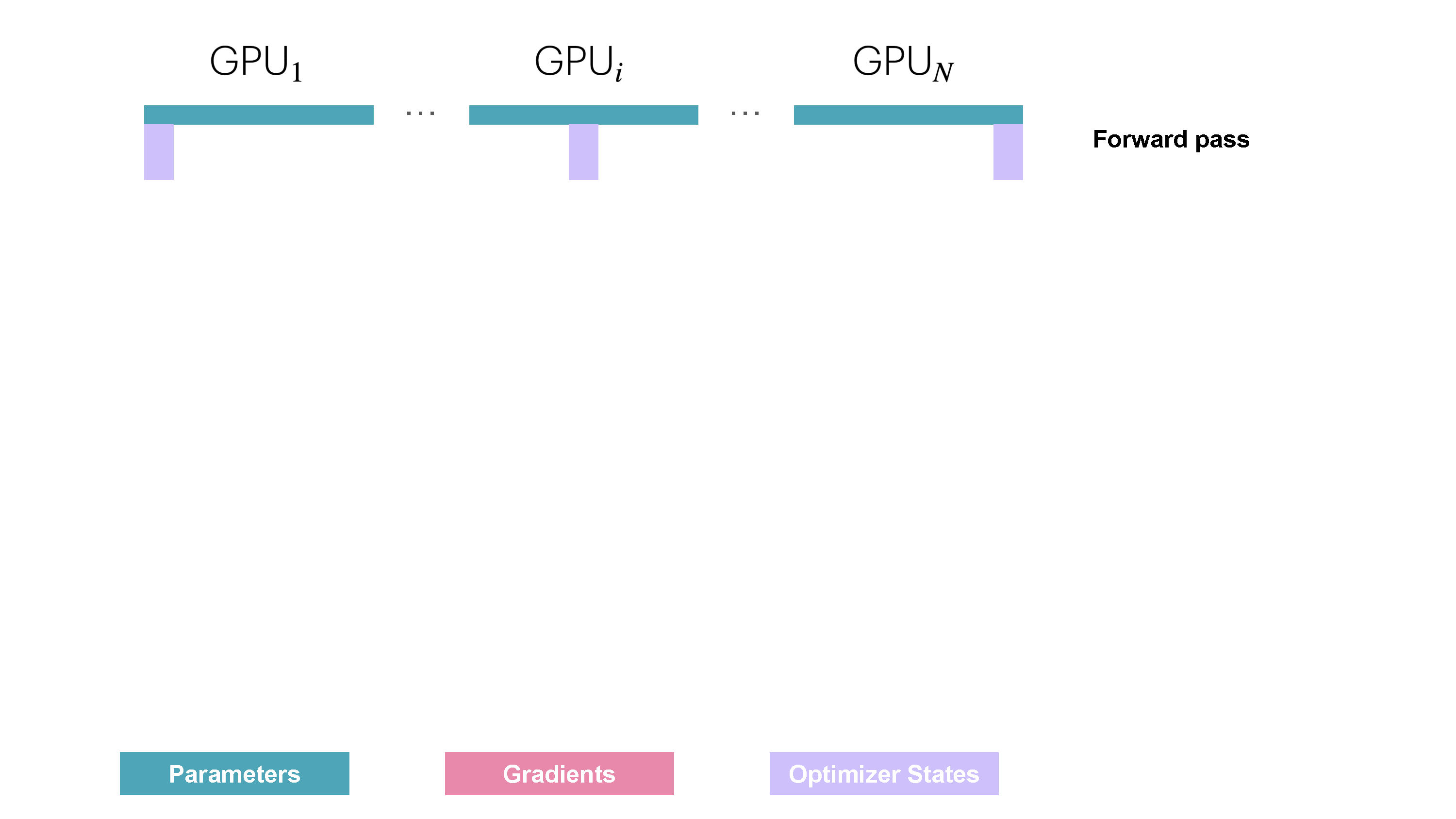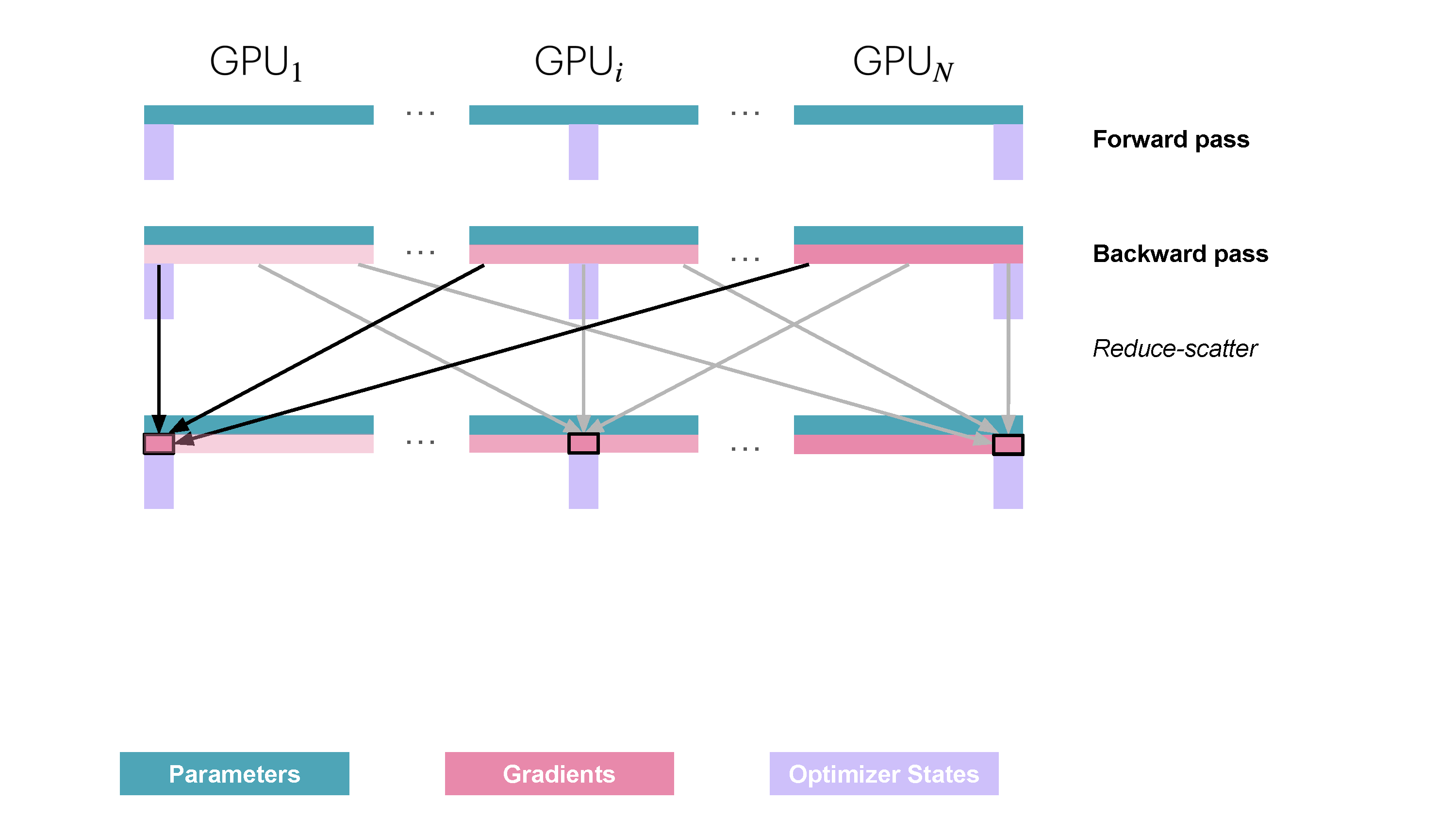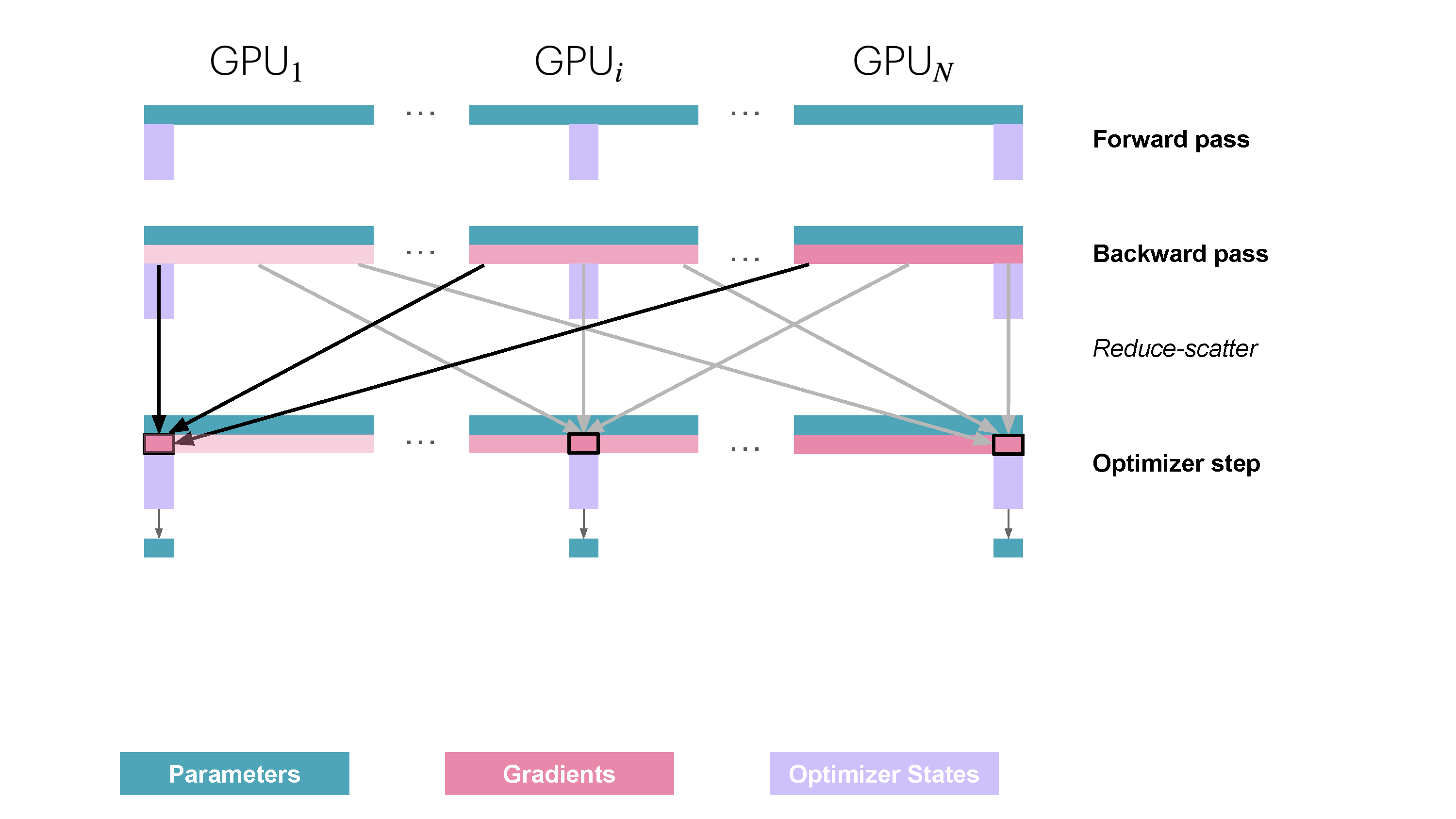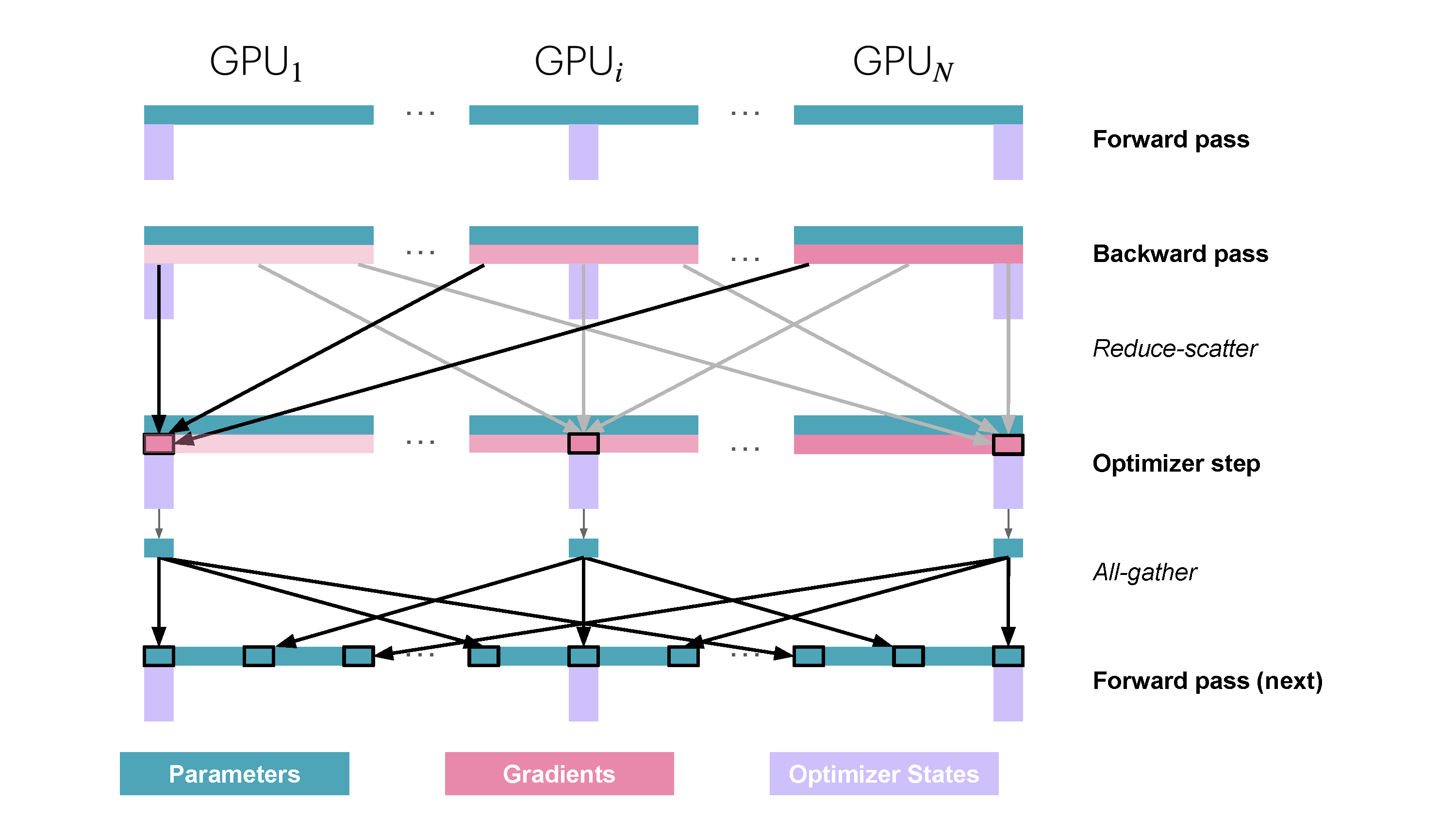
整体如上,但是问题是相较于之前的版本,多了一次all_gather操作

好在在实际情况中,既可以把优化步和参数的all_gather做重合,甚至之后的前向传播也可以。就实现而言就相对复杂了一些,需要实现对应的桶和钩子函数,不过这一点后续再说。
ZeRO2的图前面看到了,就是在优化状态的基础上继续对梯度也做分区,由于优化状态和梯度在某种程度上是一一对应的,因此可以自然的想到对优化状态做相同的操作,反向传播完成后就将对应的数据进行reduce_scatter操作:
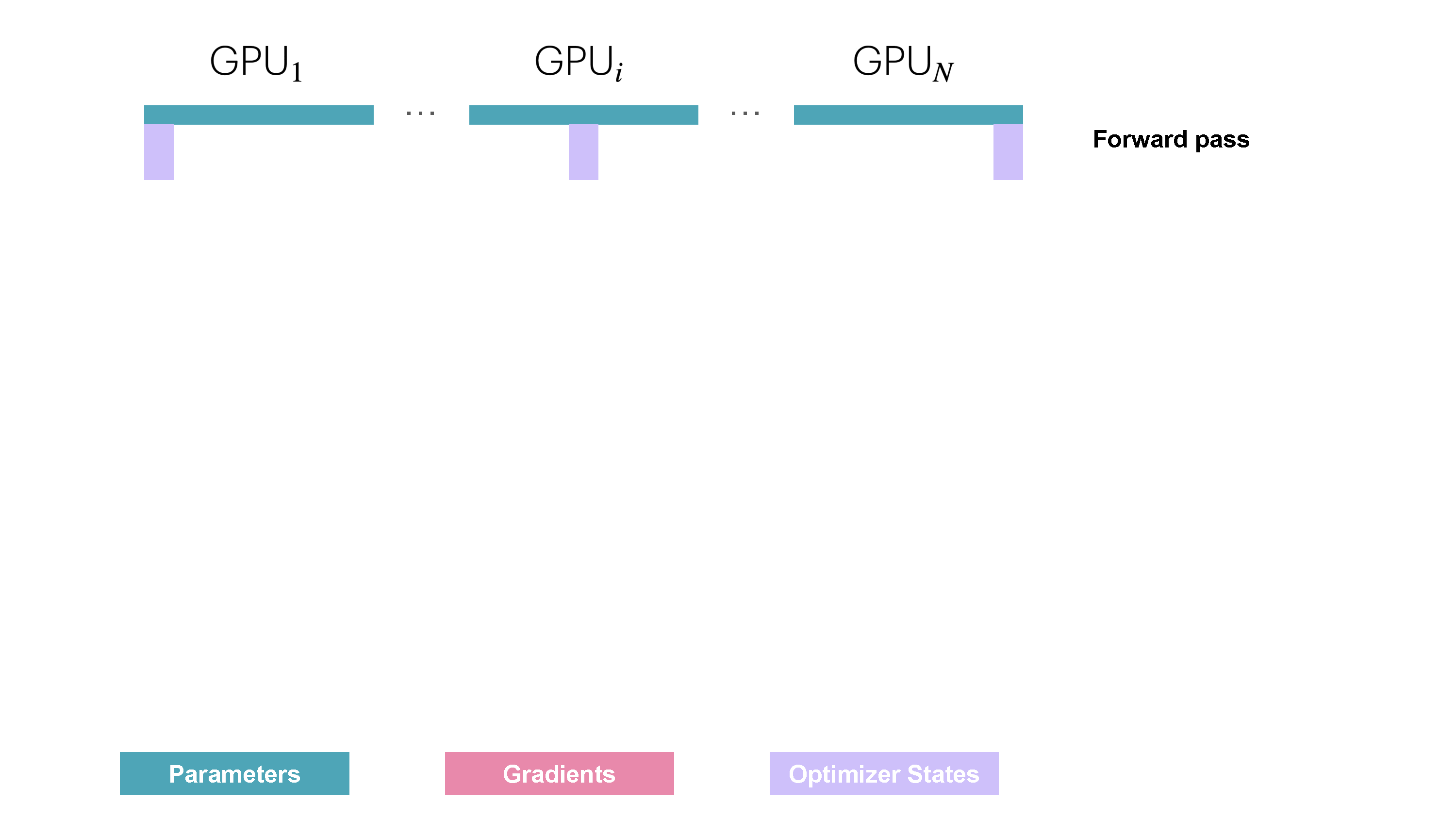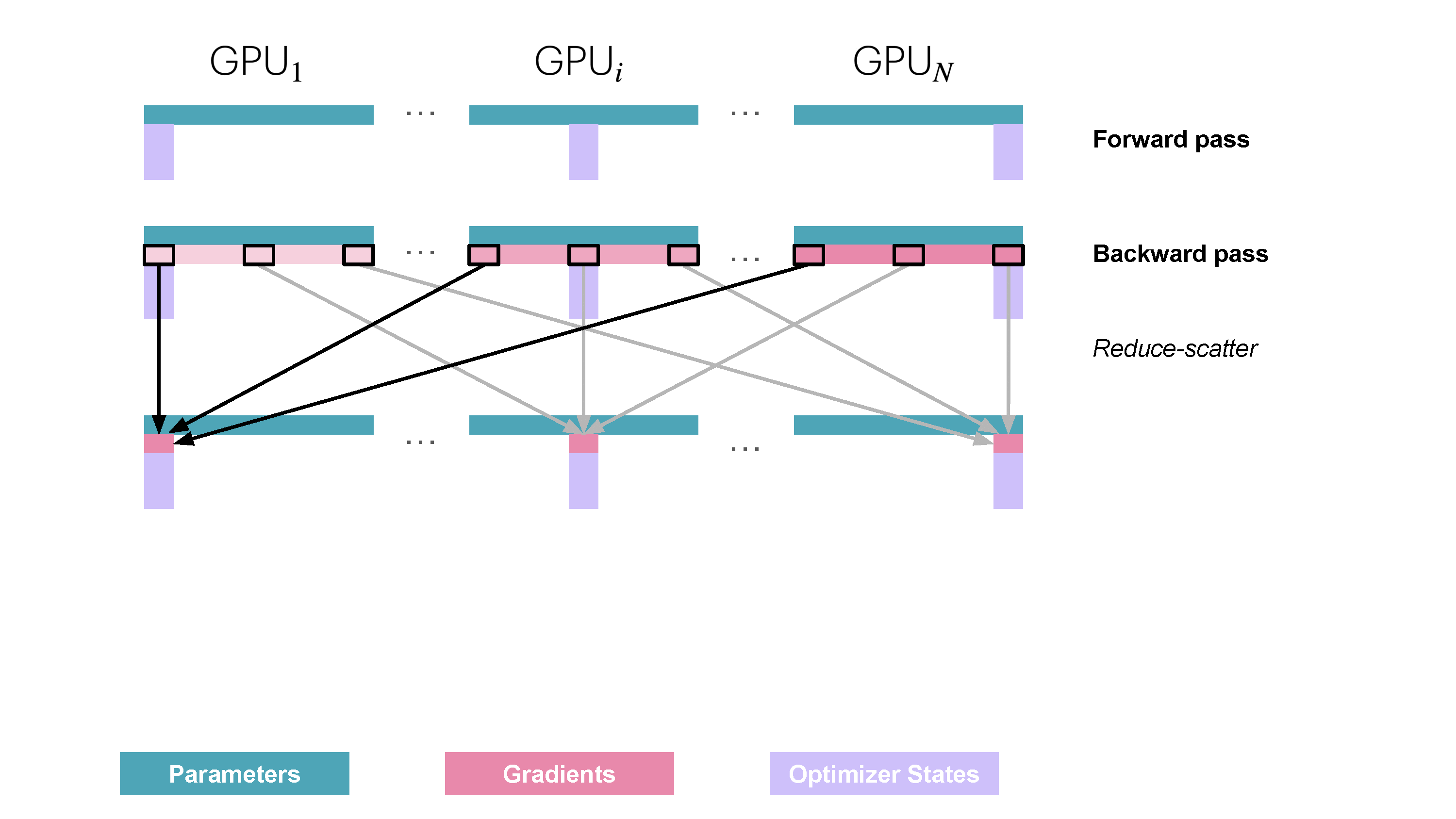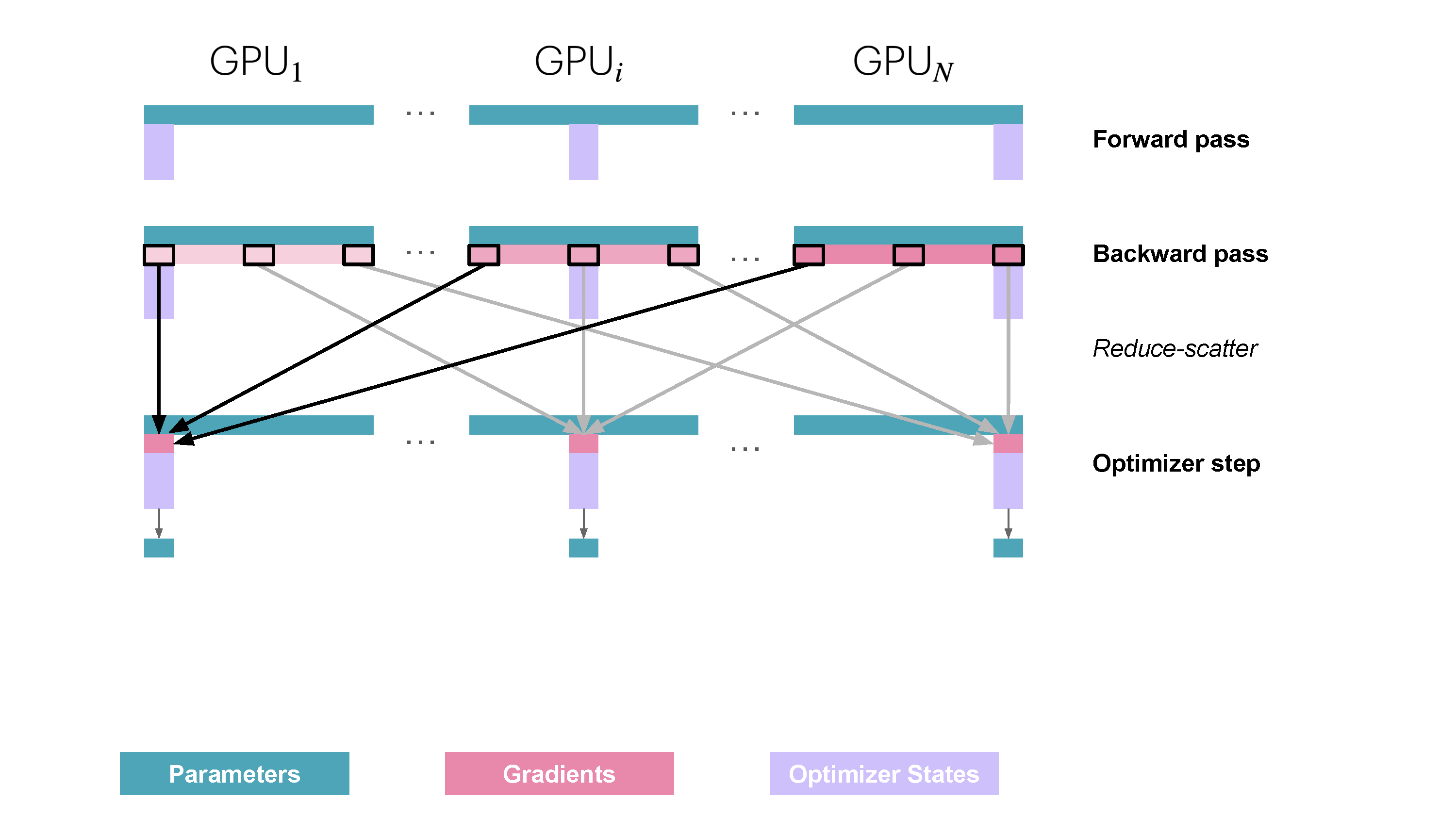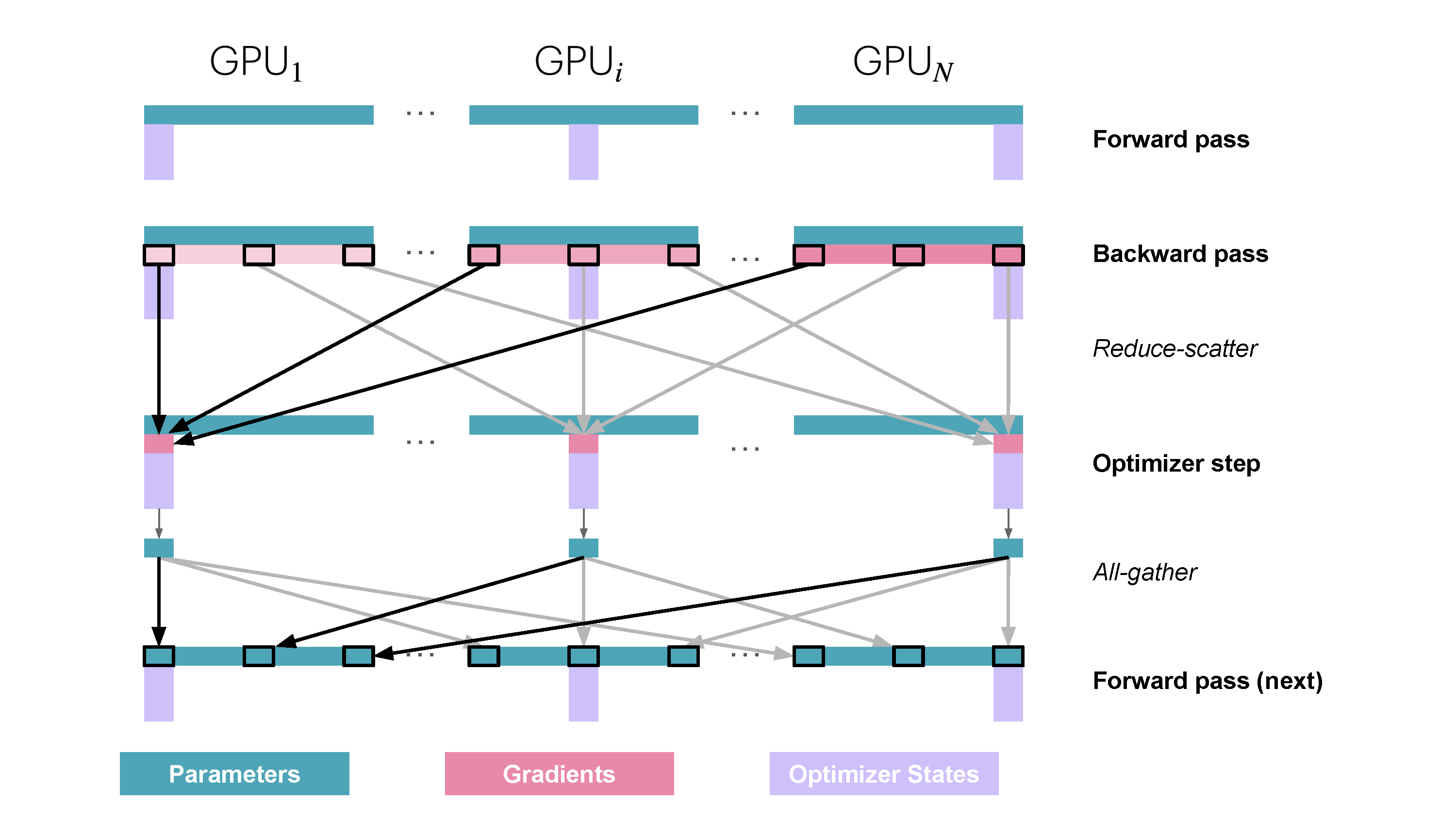
当然上述的操作减少了内存占用,而且由于这部分可以在backward继续overlap,因此相较于ZeRO1算是一个免费的午餐。

但是既然梯度和优化器状态都分区了,在往前深一步的话就可以考虑模型的参数分区了,也就是接下来要学到的ZeRO3(其实也可以叫作 FSDP (Fully Shared Data Parallelism))
根据自回归模型的推理方式,最容易想到的其实是把每个attn block分配到对应的设备上,但是问题是这样会导致一个前向甚至反向的依赖过程,从而产生大量气泡,因此一个可能的手段并不是根据block划分,而是使用TP张量并行的手段。

当然,这样的问题也很明显,每一层都需要进行all gather操作,好在每一层的参数量总体不大,因此并不算特别严重的问题。因此整体的气泡图如下:

考虑到ZeRO2需要传递优化器状态和梯度从而带来2倍于参数量的开销,这种对前向传播做分片的操作同样会带来等同于参数量的开销。通常来说这似乎带来了更大的通讯延迟,但是如果说可以在上一层计算的时候就把下一层的数据实现all-gather,那么显然是非常可取的,也因此算是一个免费的午餐。
因此从某种角度而言,如果能够实现高效的all gather和all reduce操作的话,最好的方法就是尽可能大的提升DP程度,从而实现$P/N_{dp}$程度的内存减少。
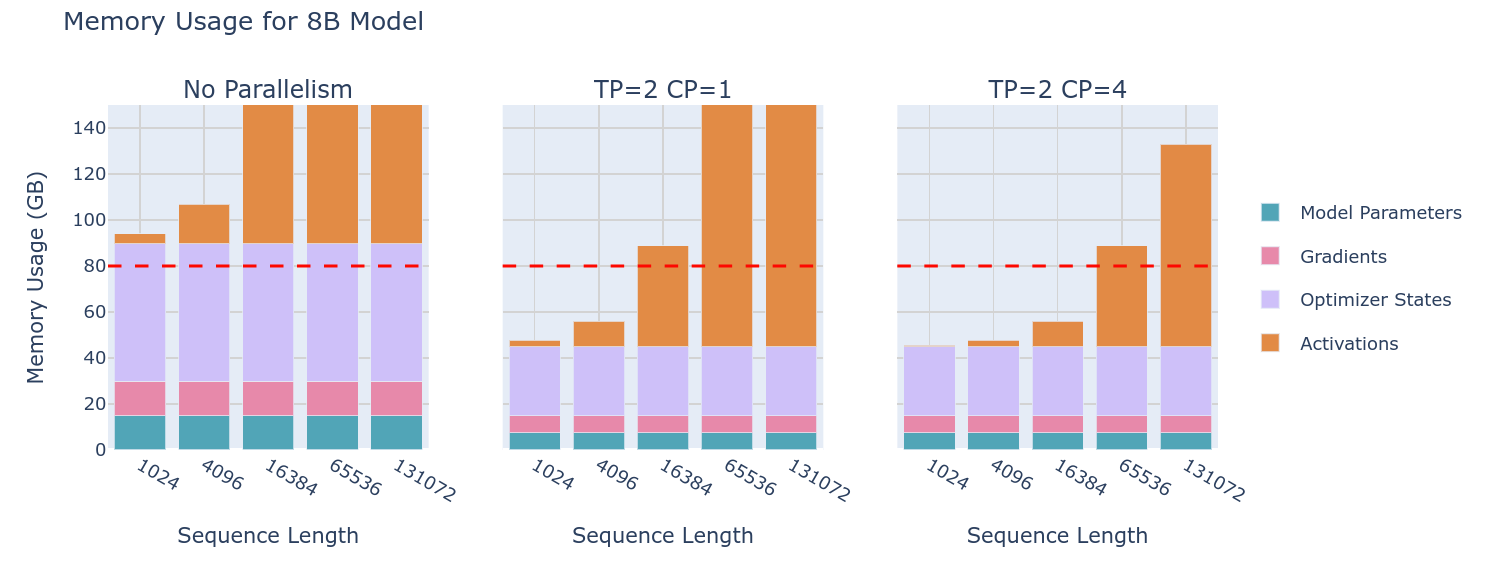
然而问题还是存在的,虽然我们减少了设备存储模型的内存,但是当存在一个较大的模型和较小的设备数量(一个设备放不下对应的参数)或者在较大的batch/seq len的情况下,情况就不一样了:
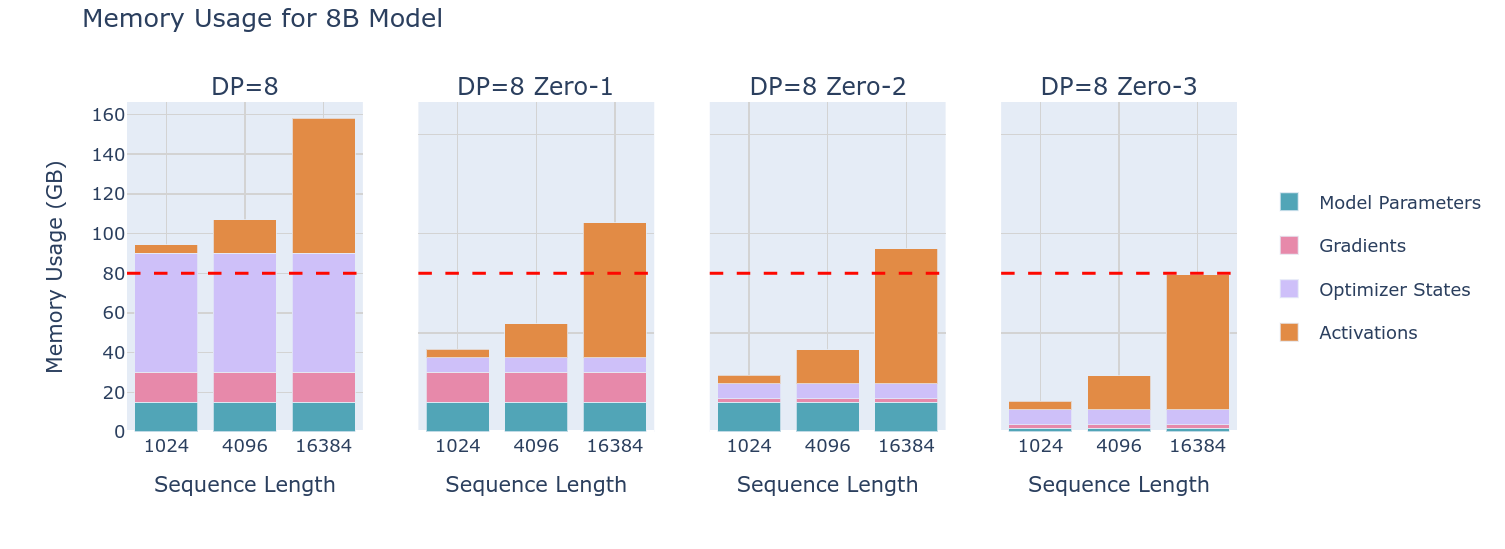
从图中可以看到,对于8B的大型模型,尽管使用ZeRO可以大幅度减少模型参数从而使得最终可以在设备中放下,但是问题在于现代的大模型往往有着远高于8B的参数量,这种方式显然就无法实现了。此时限制显存的重要因素已经变成了激活值。因此下一个手段就是:张量并行
张量并行TP
DP利用通讯原语尽可能减少了训练过程中的一些显存占用,但是现在问题在于激活值的存储上,因此这时候可以引入新的并行方式——基于矩阵乘法做并行优化而且不需要通讯的优雅(好吧其实需要)并行方法。张量并行其实并不算一个特别复杂的内容,但是核心涉及到了矩阵乘法。所以可以核心说明一下,这里拿两张图说明一下:

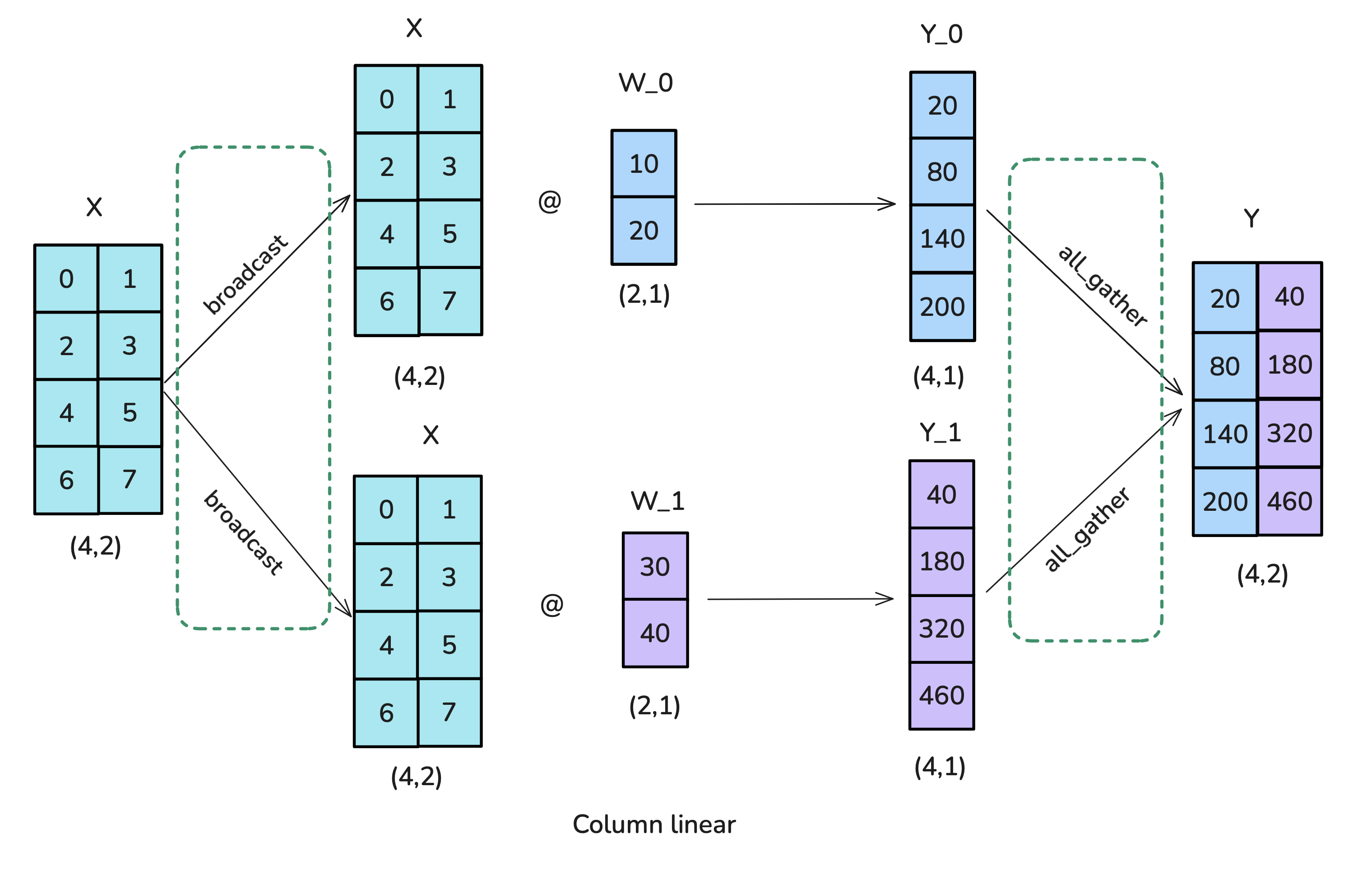
其实原理也很简单,对于上述这样一个列的线性层,由于每一列数据不相互依赖,因此可以将数据X拷贝多份,与此同时权重按照列进行划分,完成计算之后重新gather即可。当然类似的还有行线性层并行,这种情况下需要将数据按列划分之后计算(相较于上面做的是相加运算):

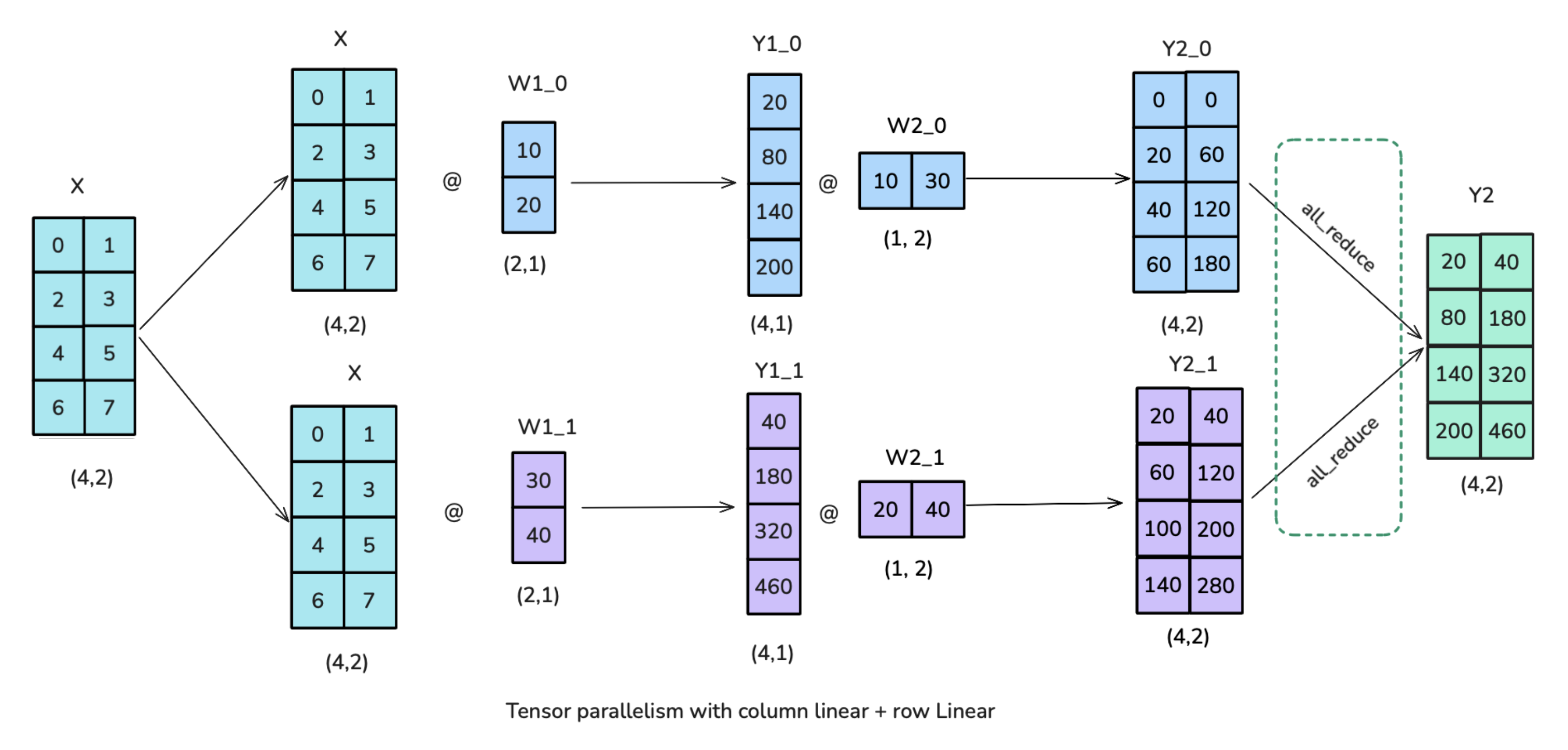
现阶段的Transformer大模型每个block通常是由MHA和FFN组成的,上述的并行方式可以很好的应用于FFN部分:
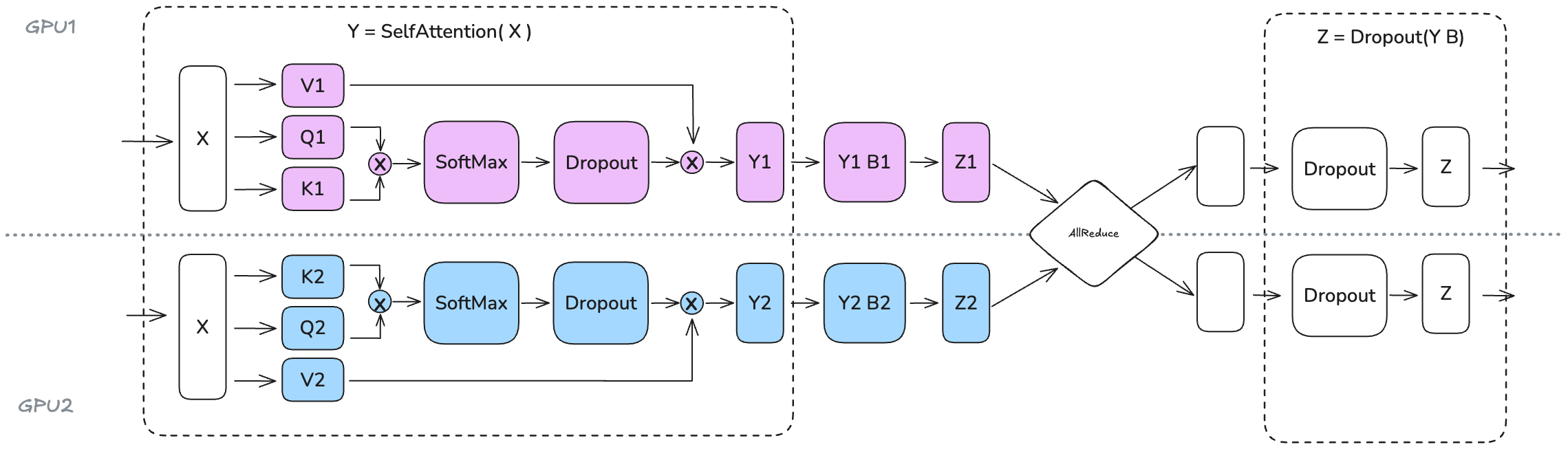
接下来是对于MHA部分,其实MHA或者GQA本身根据头就可以原生的实现比较舒服的并行(要注意的一点是,通常会要求TP度小于头数,否则多个TP分一个头的时候需要考量一下同步问题),因此整体的计算如下:
TP是一个很舒服的操作,很简单并能有效的应用,但是一个比较难受的问题在于上述的计算是会存在依赖的,尽管FFN的前向传播中采用了这种方式并行,但是由于在此之后需要进行layernorm操作,会需要一个AR的等待时间,从而产生一个气泡,如下:

因此TP并不是训练的silver bullet,好在其还是在很大程度上减少了训练过程中激活值的存储。
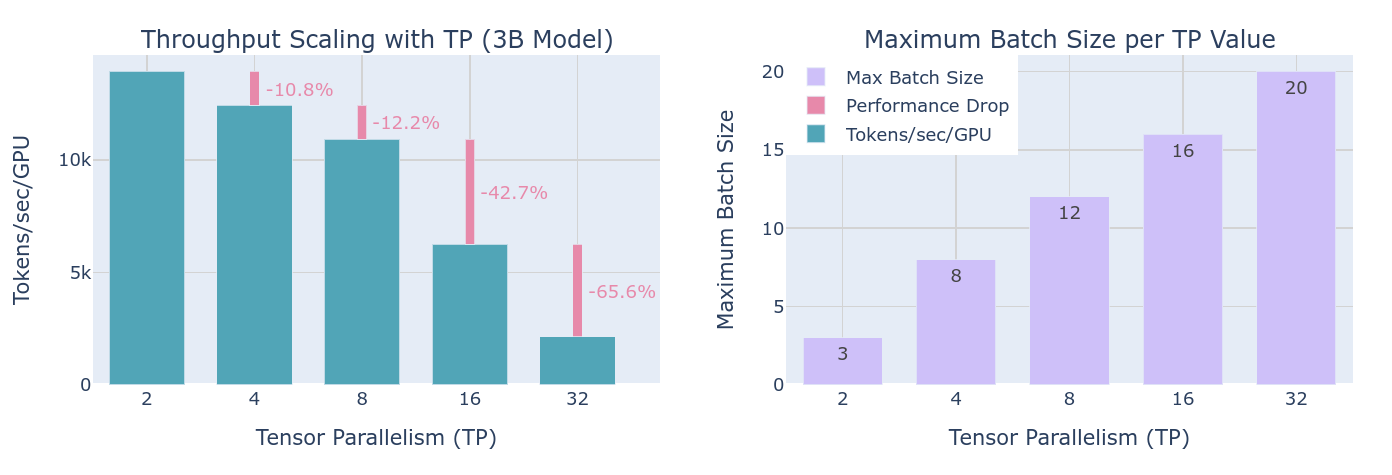
从上图可以看到,通过提高TP,虽然说可以提高训练时各个设备的batch size值,但是同时也由于通讯降低了整体的吞吐量。值得注意的一点是,随着TP的程度超过一个节点的设备数量,节点间的网络带宽将会成为一个较大的问题,单节点可以利用NVLink等手段迅速交换参数和激活值,但是对于网络通讯而言确实存在较大的延迟。
尽管存在这样的问题,但是我们总算可以在较小的设备上放下更长的seq了:
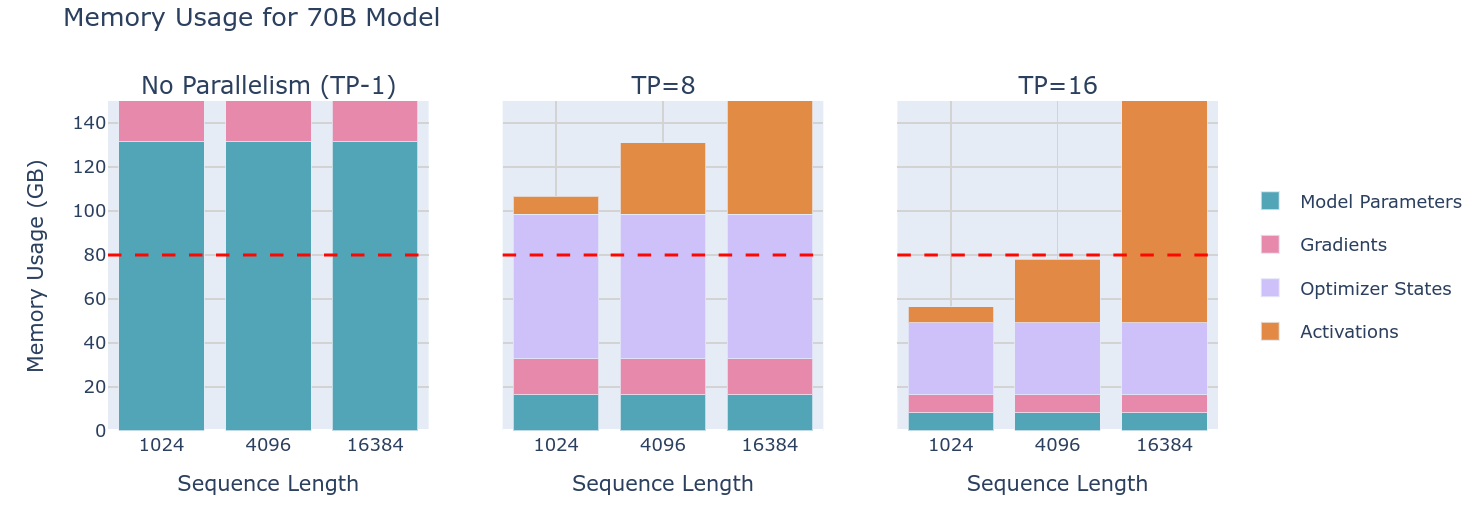
由于前面提到了TP可以将权重拆分,因此在各个程度上TP其实也能减轻梯度、优化器状态、权重的存储要求,从而使得80GB显卡允许训练70B模型了。
尽管上面通过DP可以减小激活值,但是从细粒度考虑的话,其实整个Transformer还没有被优化到的基本上只有layernorm,dropout以及MoE了。接下来就利用SP来解决Layernorm的问题。
序列并行SP
序列自然指的是一个seq,由于layernorm,dropout是对一个序列进行的操作,因此在FFN之后会被卡一下(至于为什么这么做,其实是算法和性能的问题,这里就不多说明了)。(由于序列并行部分也会涉及到长序列的并行,通常会需要使用额外的方法,比如Ring-Attention等,虽说也是做序列并行的,但是这种情况我们更倾向于叫作上下文并行Context Parallelism)
关于L N的相关操作就不重复说明了,那么如何将SP融入到Transformer中,参见下图:
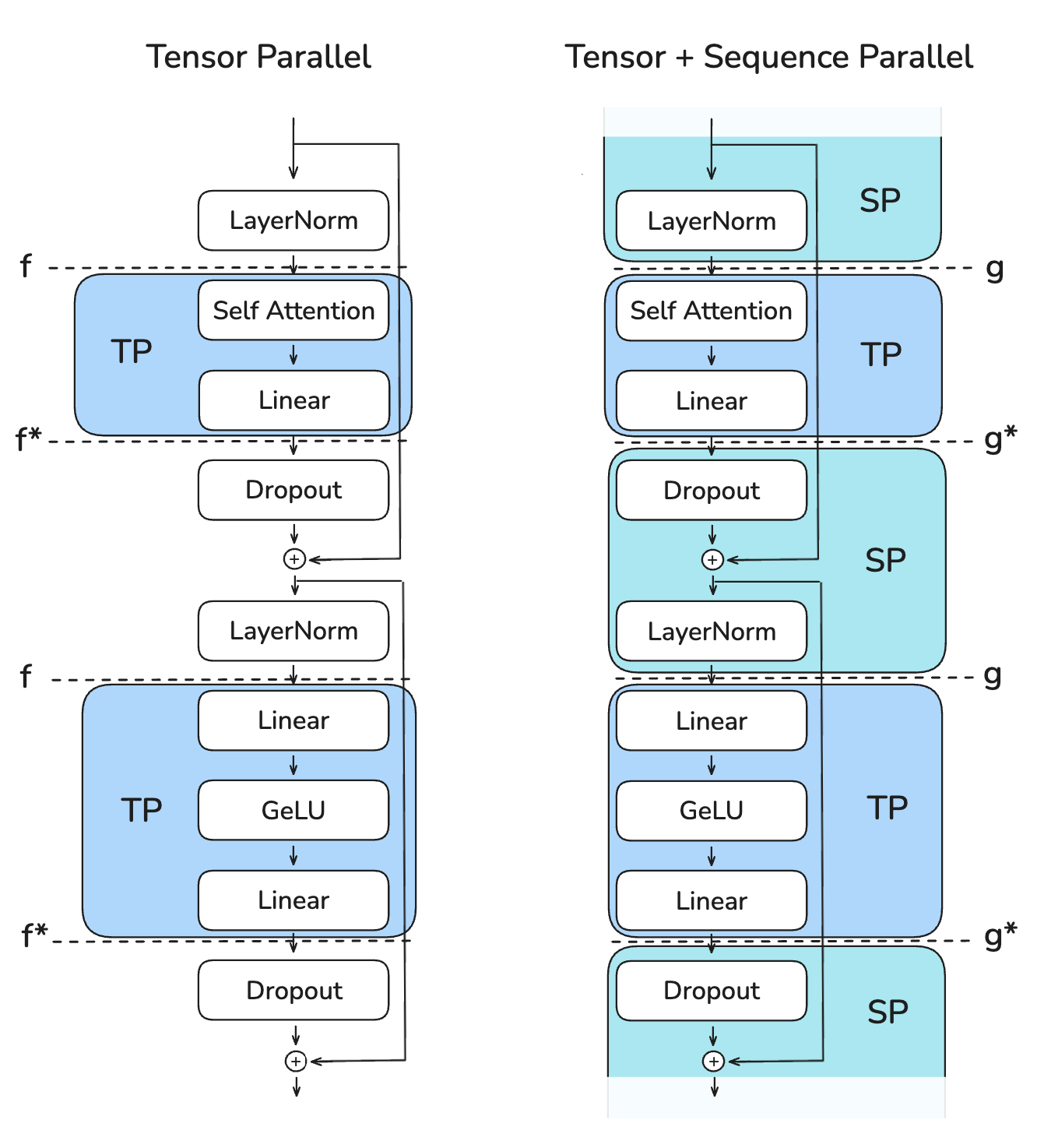
其实也算是相当好理解的了。相较于只有TP的情况,显然我们需要将每一次TP的数据做一个AR操作,之后丢入到LN中,所以为了解决,就是在此之前用一下SP操作,细节如下:一步一步来
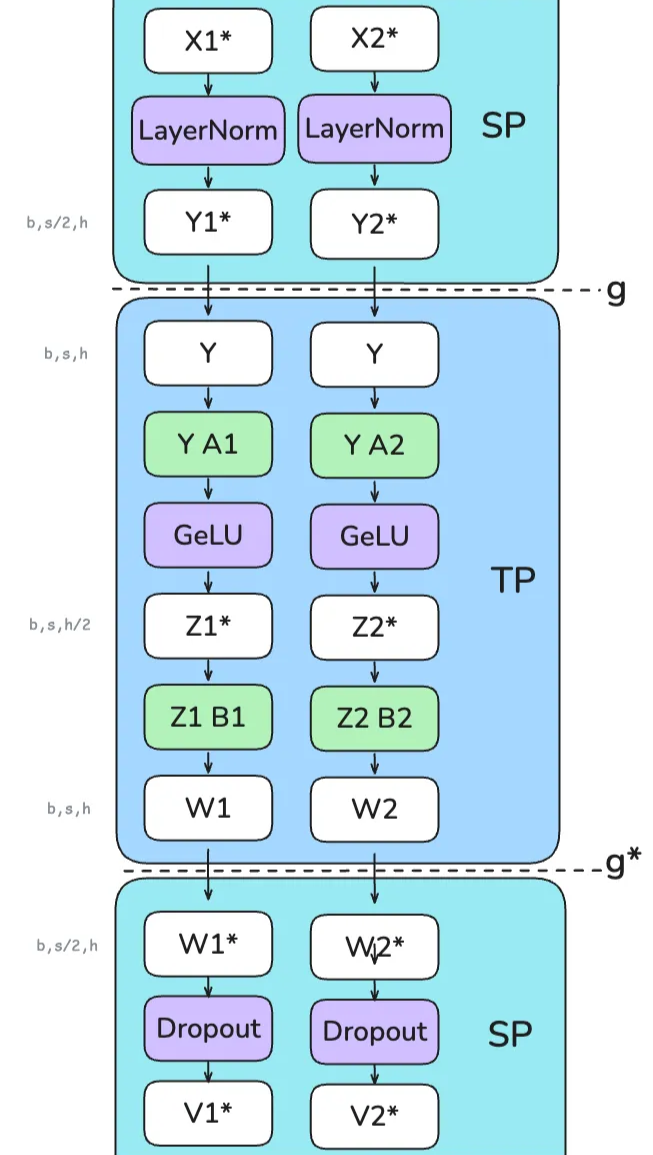
- 将两个序列X分成X1和X2进行SP,在两个设备上分别计算LN操作,之后将得到的内容AR
- 对于TP就是上面的操作,只不过在最后先做一个Reduce之后按照Seq重新切分
要注意的一点是,TP仍然是为了解决内存的问题而不是提高计算性能,因此接下来:
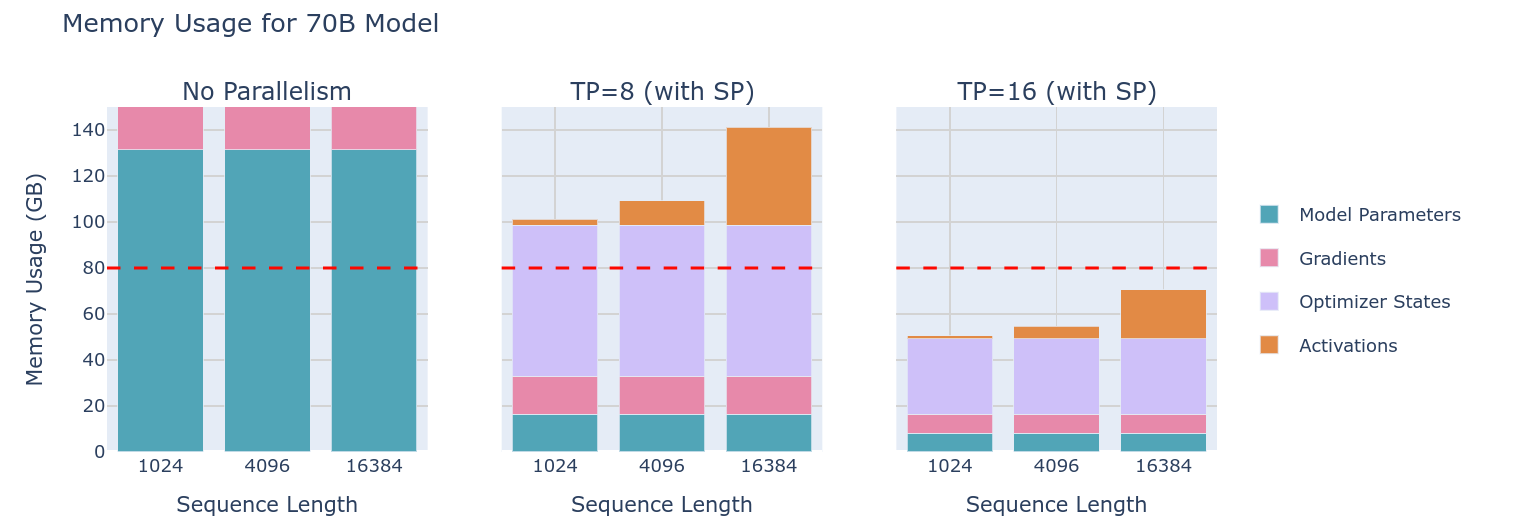
利用TP,可以进一步的降低整体的显存占用,从而使得训练完全可能了。
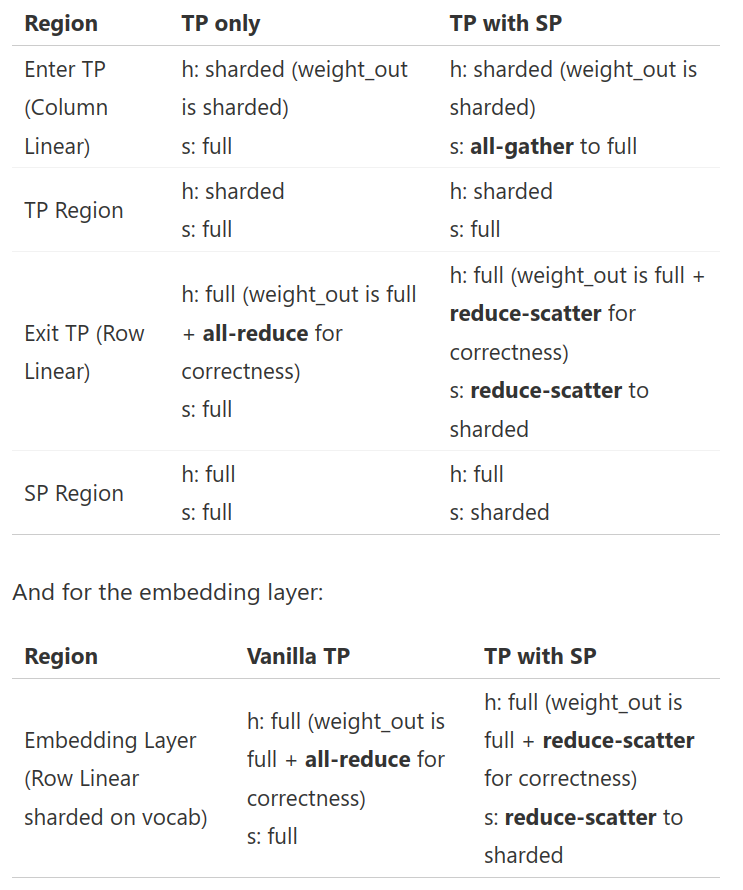
然而考虑到通讯效率时,有一点奇怪的是,尽管SP需要额外的两次all gather操作,而TP需要两次AR和SR操作,因此其实是增加了通讯量?其实并不然,因为TP的AR其实就是SP所需要的AR操作,因此这种TP算是一个free的操作。

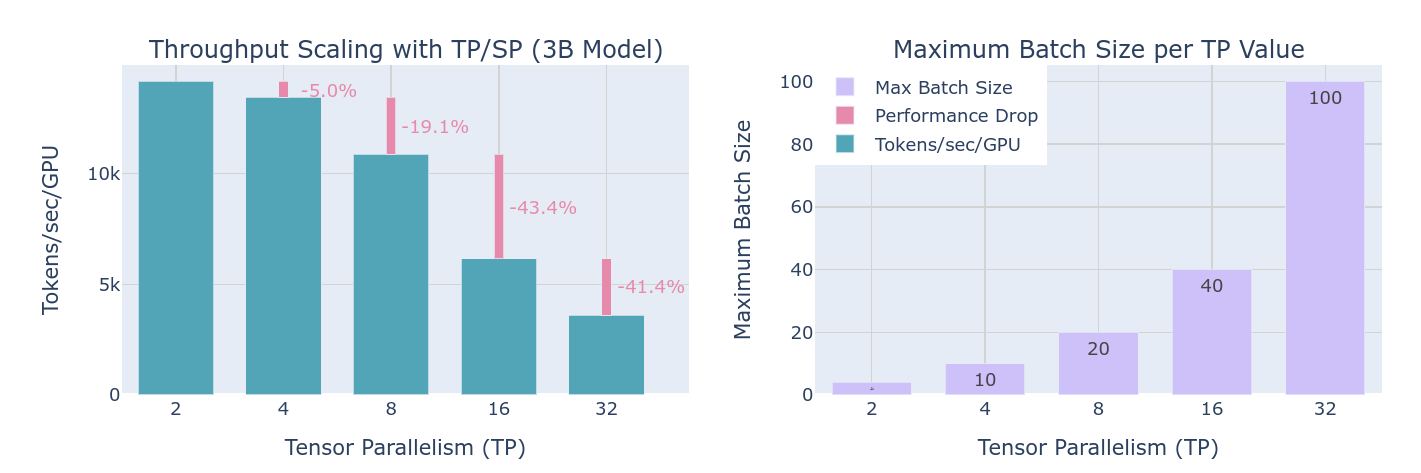
因此相较于前面的TP版本,实际上并没有增加更多的通讯代价,吞吐量在相对有所提升的同时,batchsize也得到了大量提升。
当然,我们的需求远不止于70B的勉强训练和3B的大规模训练,随着模型的参数提升,同样会遇到瓶颈:
- 在TP AR的部分会显存爆炸一下
- 模型在TP=8的情况下还是放不下的时候
对于上述的两个问题,分别用接下来的两种方案解决:上下文并行CP解决问题1,流水线并行PP解决问题2
上下文并行CP
我们用了SP和TP大幅度缓解了seqlen提升的显存占用,但是问题是,对于更长的上下文,超过128K时,上述的方法完全没用了:
对于一个Attention操作,进行QK计算时,实际上需要一个Seq的参与,由于在QK计算时需要整个seq的参与,不仅会带来等同于seqlen*hidden的存储,还需要存储中间的attn矩阵从而大幅度提高存储需求(当然,我们学过flash attn所以知道其实可以减少到seq的存储)。流程比较蛋疼,我们看这个动画吧:
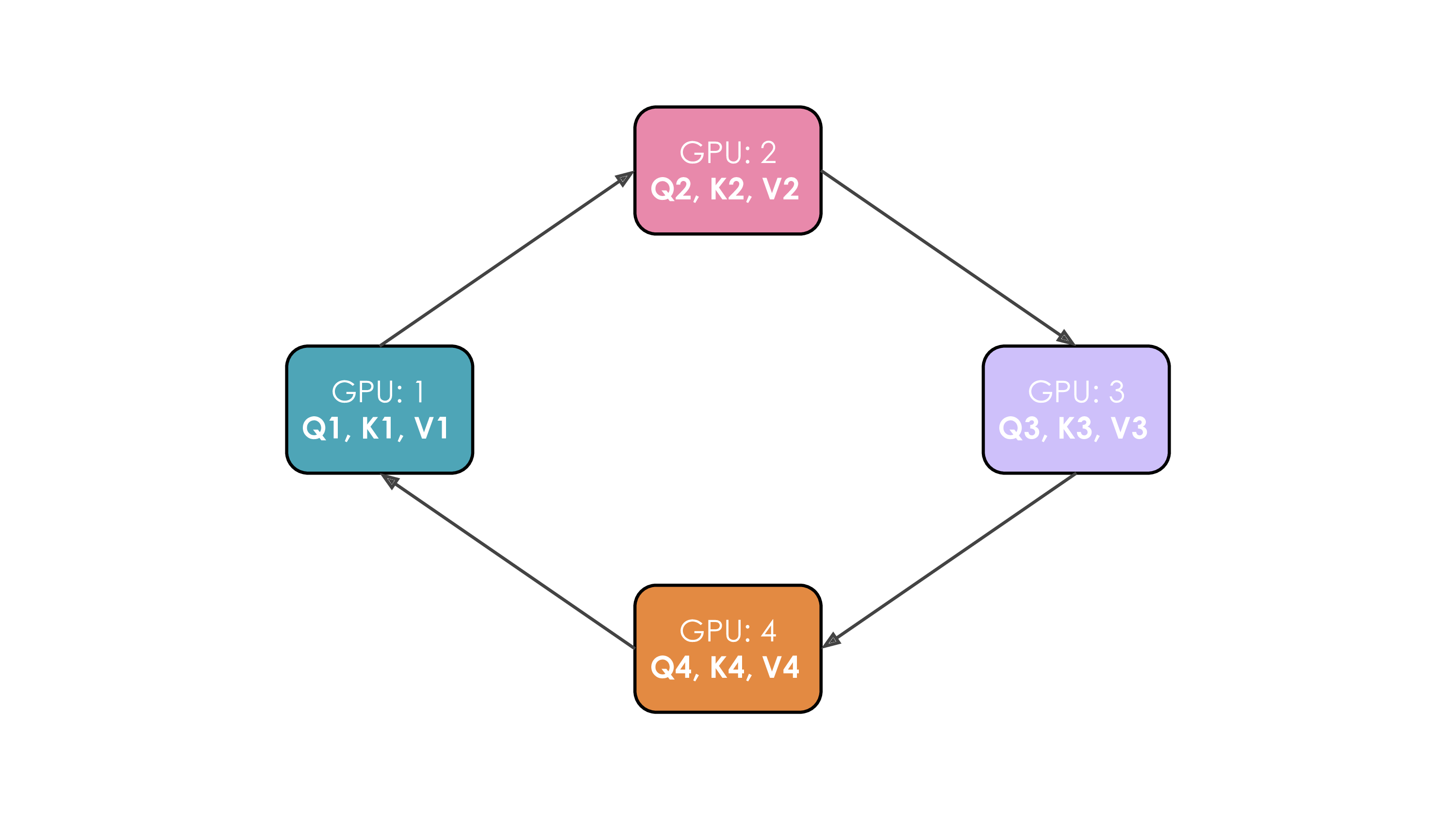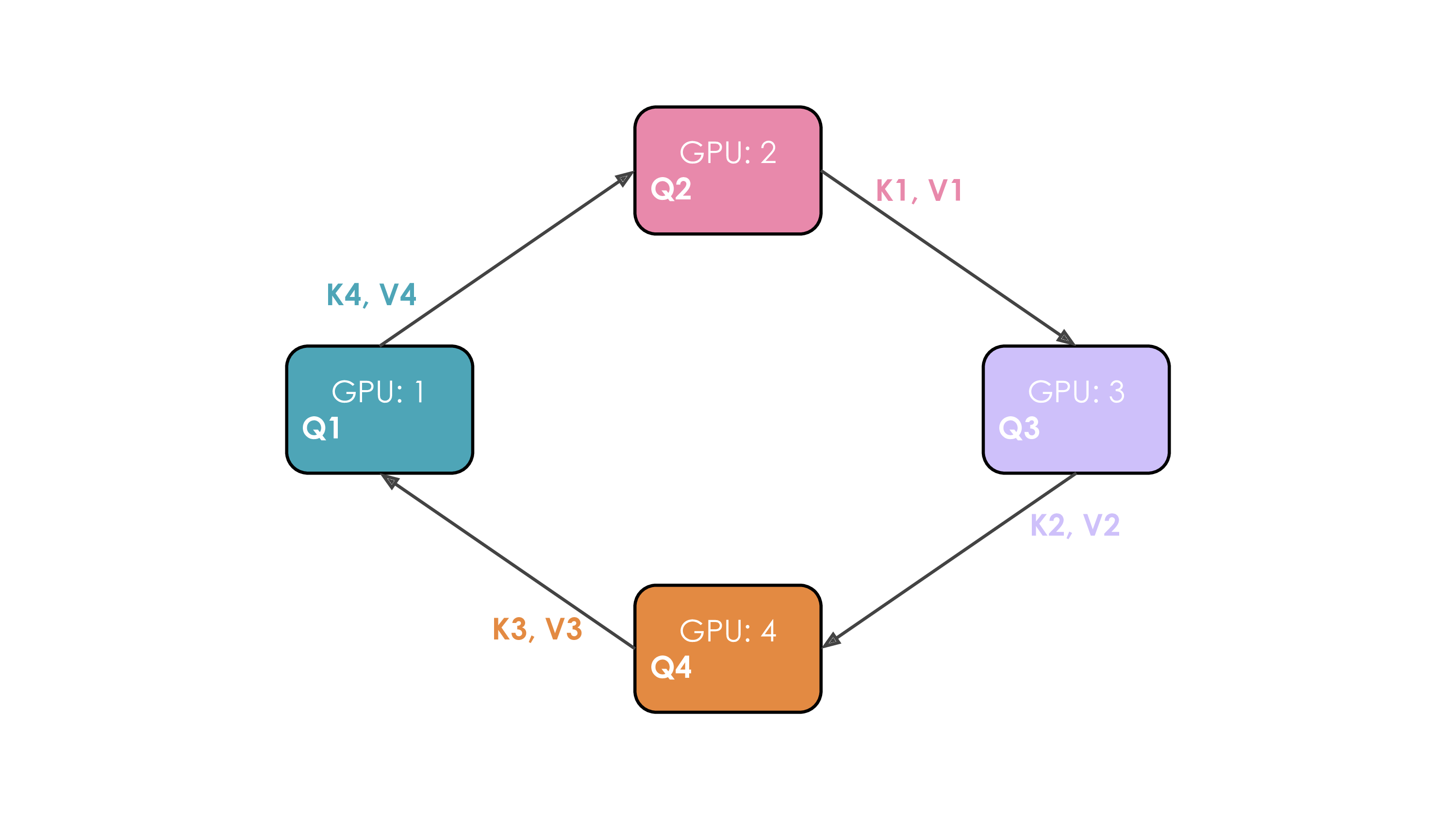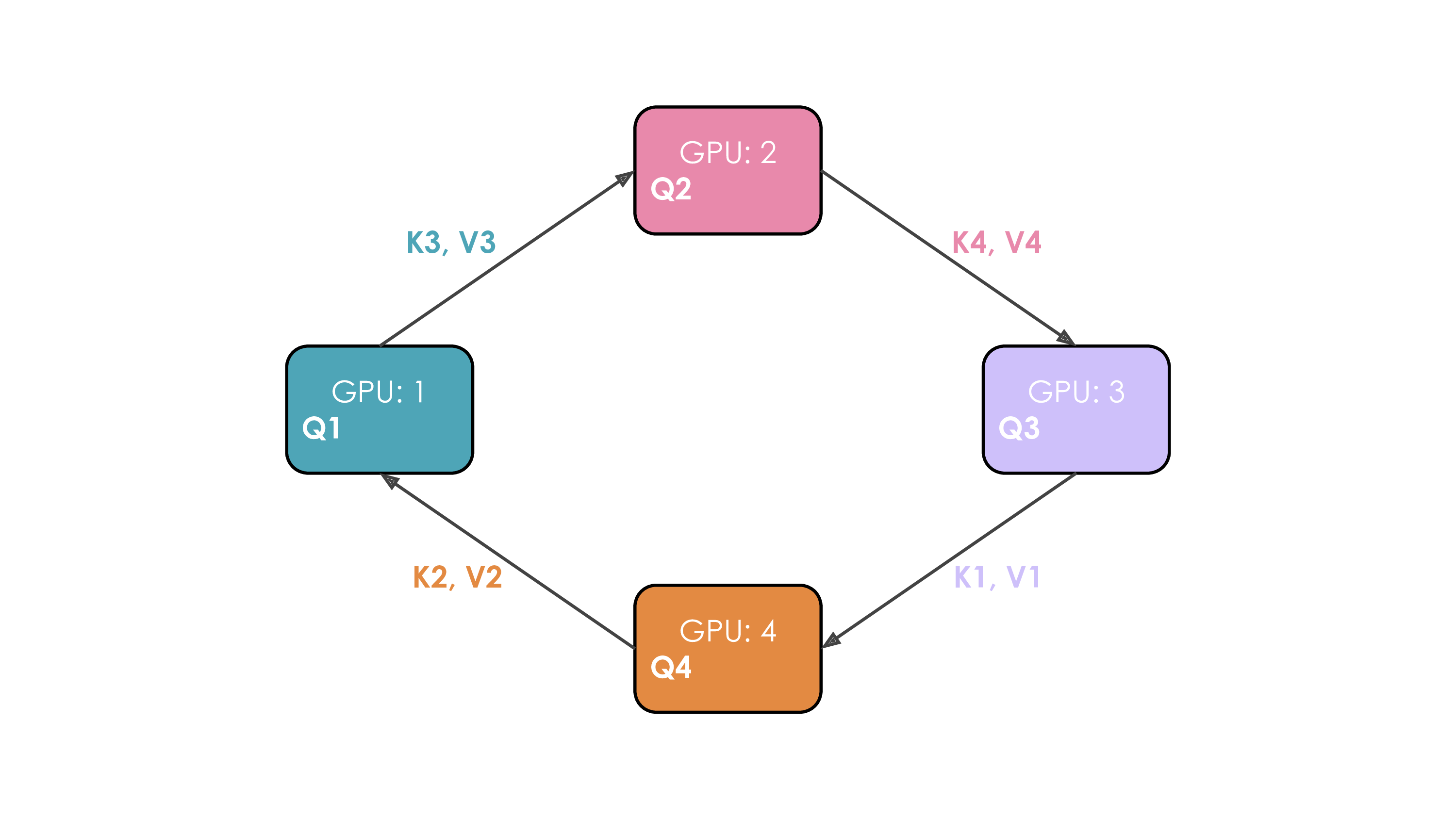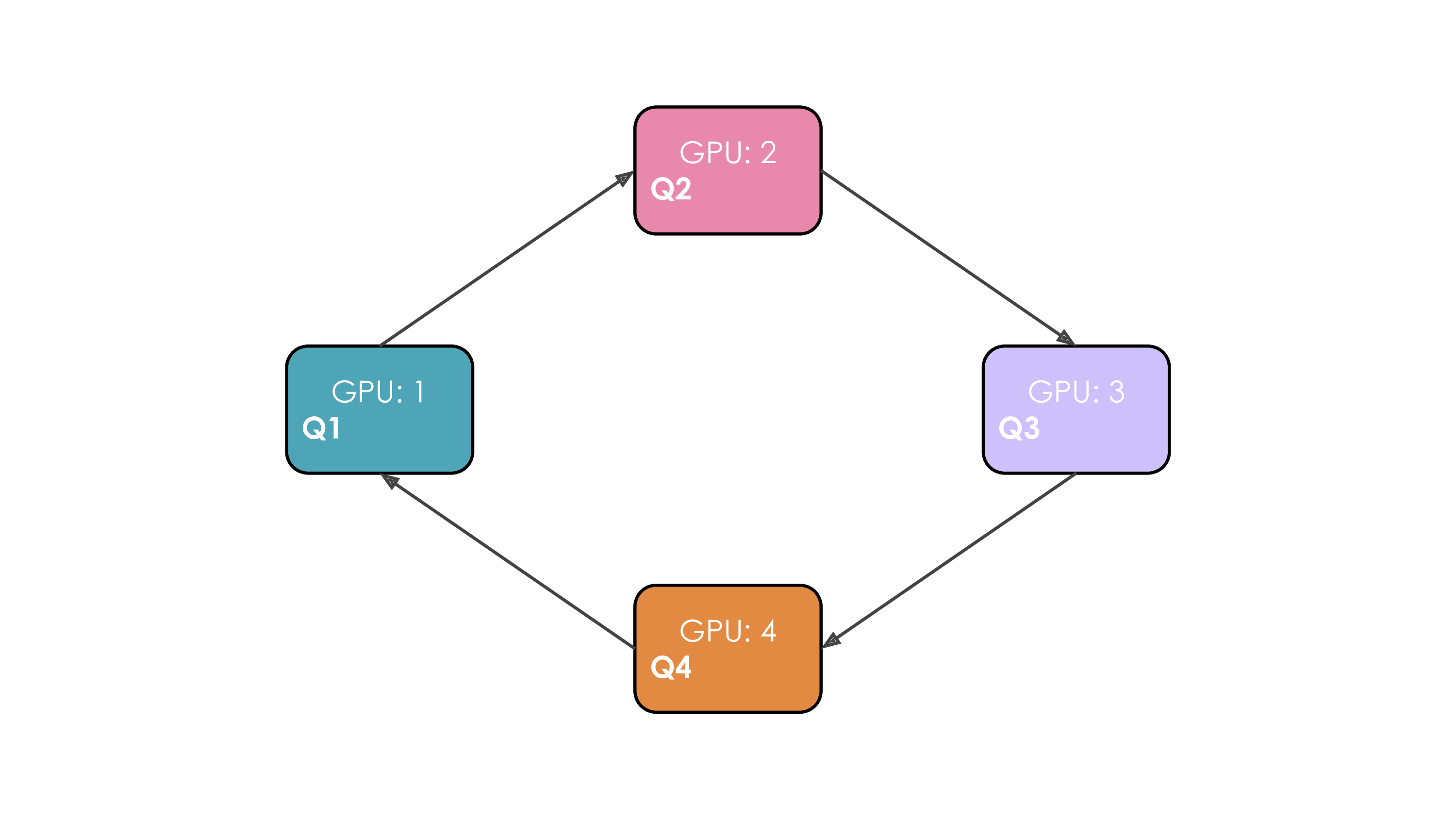
通过一个环通讯,每次将新的token对不同的kv进行计算并overlap了计算过程,但是由于现在的注意力机制都是Causal注意力机制,因此对于开始的token,计算负载会小很多:

这种实现负载均衡其实并不复杂:

这个时候,气泡图变成这个样子了:


到这里,已经可以通过CP来解决上下文的存储问题了,接下来就是解决TP未能解决的问题2,一个设备还是放不下大型的模型。
流水线并行PP
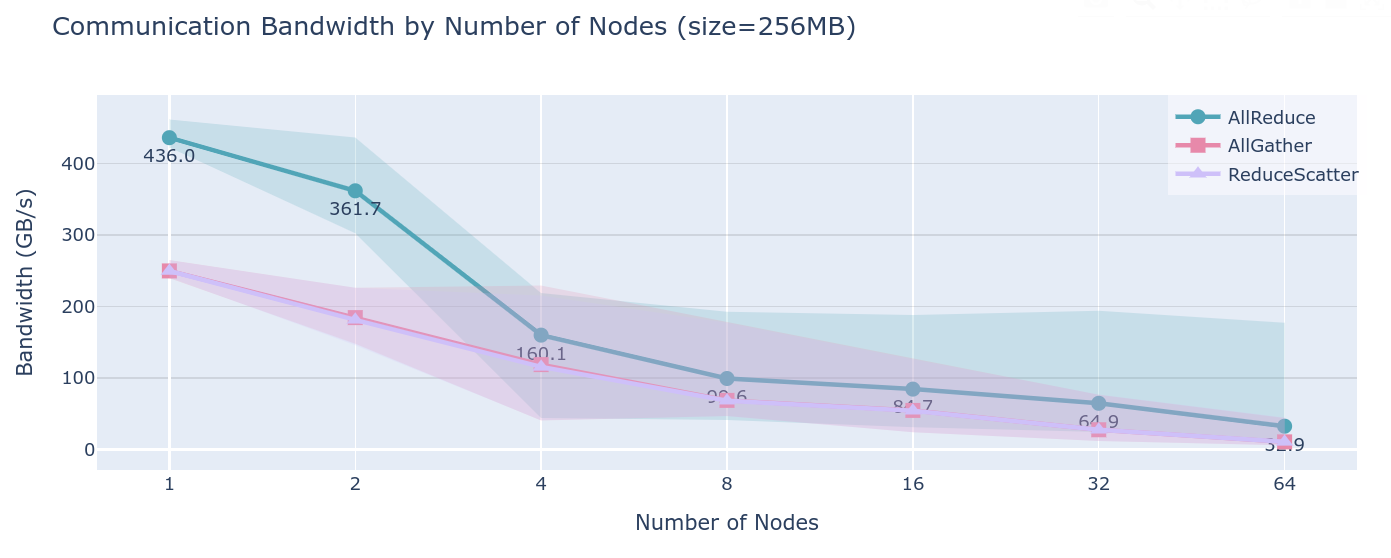
显然,超过节点数量的通讯会极大的降低性能,而且仅仅是70B的模型就足以超过4/8卡的显存,因此如何实现更加高效的通讯以应对更大的模型,这就是PP要解决的问题。
当然,PP本身并不复杂,假设现在有8GPU,只需要把0~3层放到卡1,4~7层放在卡2,以此类推。但是这个时候,由于前向和反向传播存在依赖,所以这时候就可以画出真实的的气泡图了:

尽管花了大量的功夫完成了优化,但是当扩展到大型模型的时候,PP似乎让之前的一切都丧失意义了,好在有解决手段,也就是接下来要提到的一些相关优化手法。
手段1:all-forward-all-backward (AFAB)
如果一整个batch进行上述操作会导致巨大气泡,我们可以考虑把batch划分的更小一点:

这样在一个设备计算batch2的时候第二个设备可以计算batch1,从而overlap了计算时间,大大的减少了气泡的数量,然而这只是第一种优化手段,接下来的相对来说会更加混沌一点了。
手段2:one-forward-one-backward (1F1B)
相较于上面优先实现前向传播,这种方法倾向于立即做反向传播,因此如下:

不过如果详细的看的话,其实上述方法,完全没有降低气泡,但是由于多个batch的计算会在一个设备上积累较多的激活值,因此上述手段可以降低激活值的存储数量。通过提供更多的设备其实也能降低整个过程的气泡值。
然而,从上面的图中已经可以看到了,大规模的训练需要对整个pipeline实现更加复杂的优化。
那么接下来看看我们的操作在大型模型的训练场景下如何:
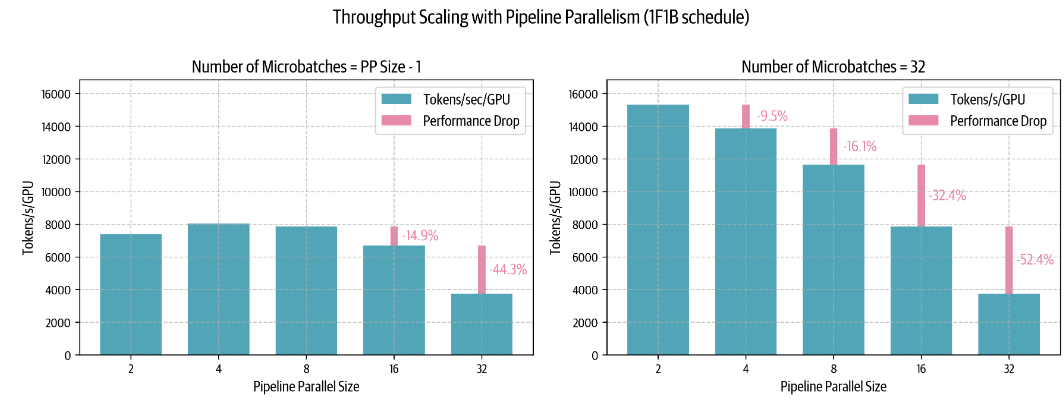
如图,随着微batch增加,上述方法能够大幅度的减少由于节点数量提高所需要的通讯,从而保证了较高的吞吐量。
此外,相较于TP,PP在节点数从8扩大到16时会有更小的损失,因此在大模型的训练其实跨节点还是更倾向于PP。
目前为止,我们的PP进入了一个非常舒适的阶段,不算特别复杂,可惜的是PP并不遵循简单的原则,相反,比较复杂的策略可能会取得更好的性能。通常来说,前面的PP都是按顺序将层放到不同的节点上的,但是也会存在交错的场景,比如下面的情况:

上图就是将0,4给卡1的情景(1,5;2,6;3,7类似的),这时候通过计算我们可以算出来气泡变少了,通过使用microbatch和交错阶段实现了更小的气泡,当然代价就是通讯代价会稍微高一点。通常情况下这是一种权衡的结果,具体还是取决于设备的性能等等。
在实际的训练场景中,有时候可能会出现更加复杂的情况,通常情况下的策略有两种:广度优先:优先让更多的microbatch加入pp,深度优先:优先让更多的microbatch进行反向传播来结束循环。对于Llama3.1,就是这样两种策略相互调度的结果。
从硬件的角度来看,气泡可能是必不可免的,然而接下来的算法通过一种方法实现了ZeroBubble,同时DeepSeek也在此基础上提出了DualPipe,这也是接下来要讲到的。
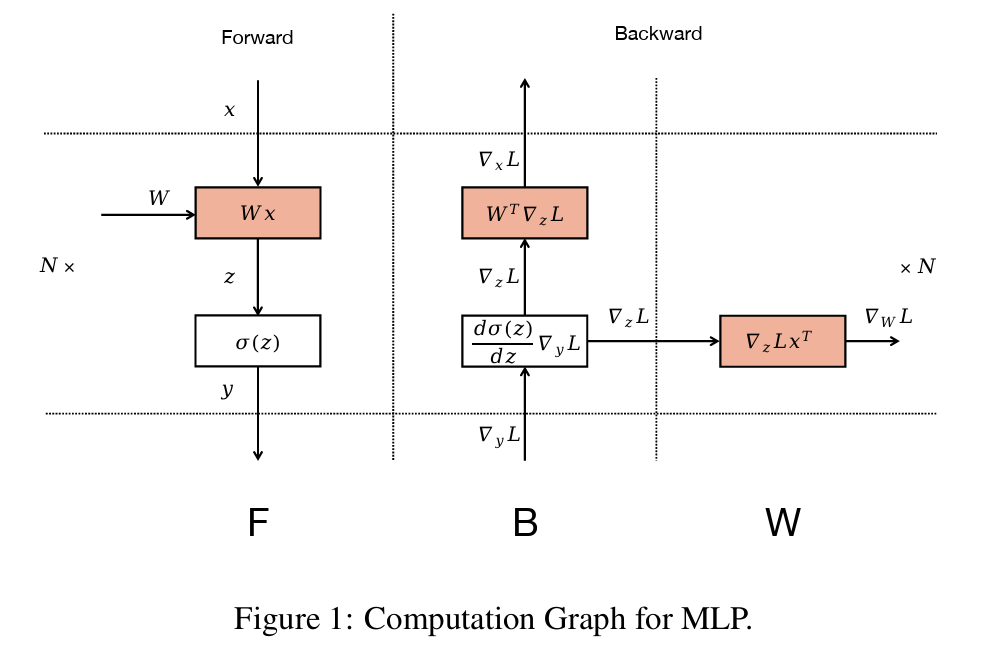
ZB算法考虑的更加细致,对于矩阵乘法而言,反向传播实际上包含两个步骤:对输入做反向传播操作(B),以及对权重(W)做反向传播,看似简单,实际上很深刻,因为这样,就能在W可以在B之后的任意时刻进行,因此可以用来填充气泡。
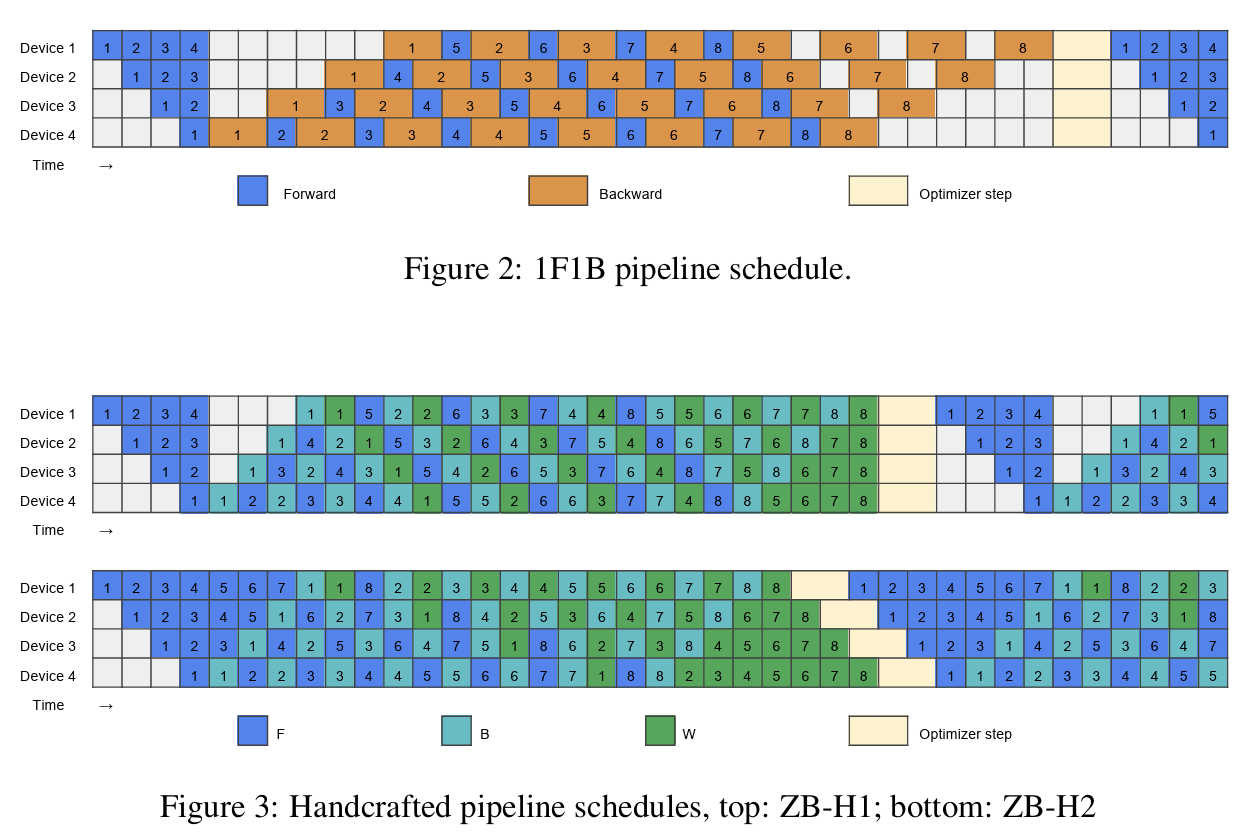
在此基础上就可以有更加复杂的设计了,比如说DeepSeek的设计:DualPipe
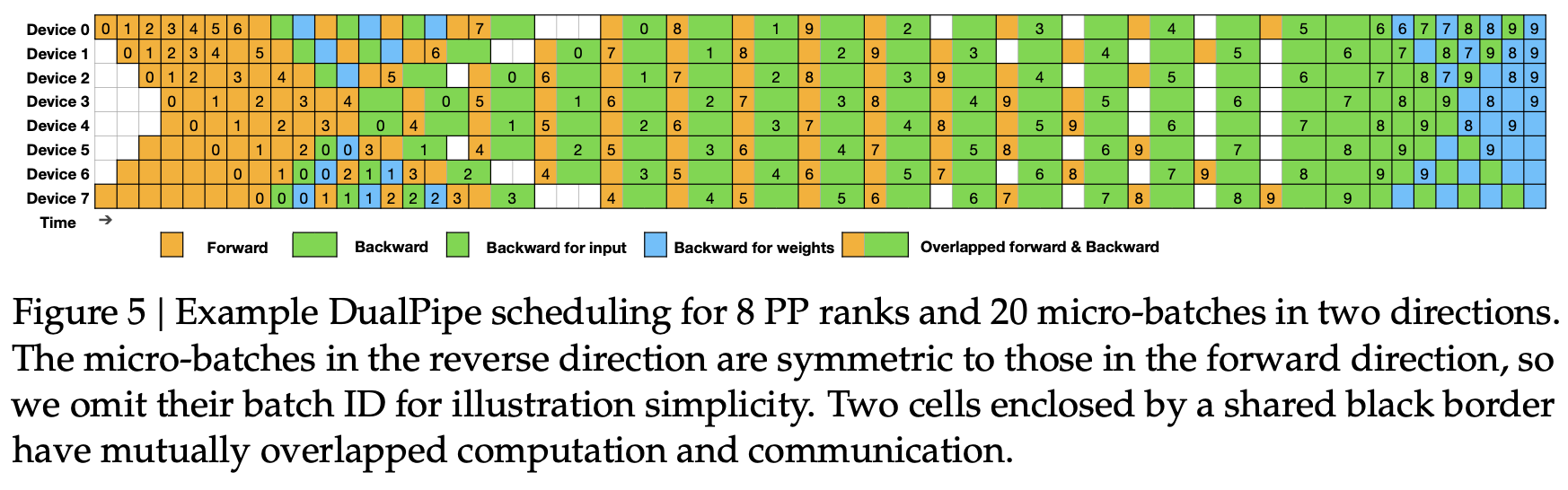
通过从双端进行PP操作从而进一步减少了整体的时间,也是非常地优雅。
当然,到此为止,其实我们就已经解决了除了显卡以外的所有问题了,但是对于LLM的优化确实永无止境,接下来的优化就是更加细致地优化:专家并行EP。
专家并行EP
关于混合专家结构其实没必要再说了,但是EP的并行实际上也算是一个有意思的课题。
EP之间由于是相对隔离的,所以可行的手段就是设备对应各自的Expert,但是Expert会遇到负载均衡的问题,除了在推理时做额外的存储,另一种手段就是在训练时尽可能实现负载均衡。
关于EP的相关内容,可以详细参考DeepSeek相关研究。
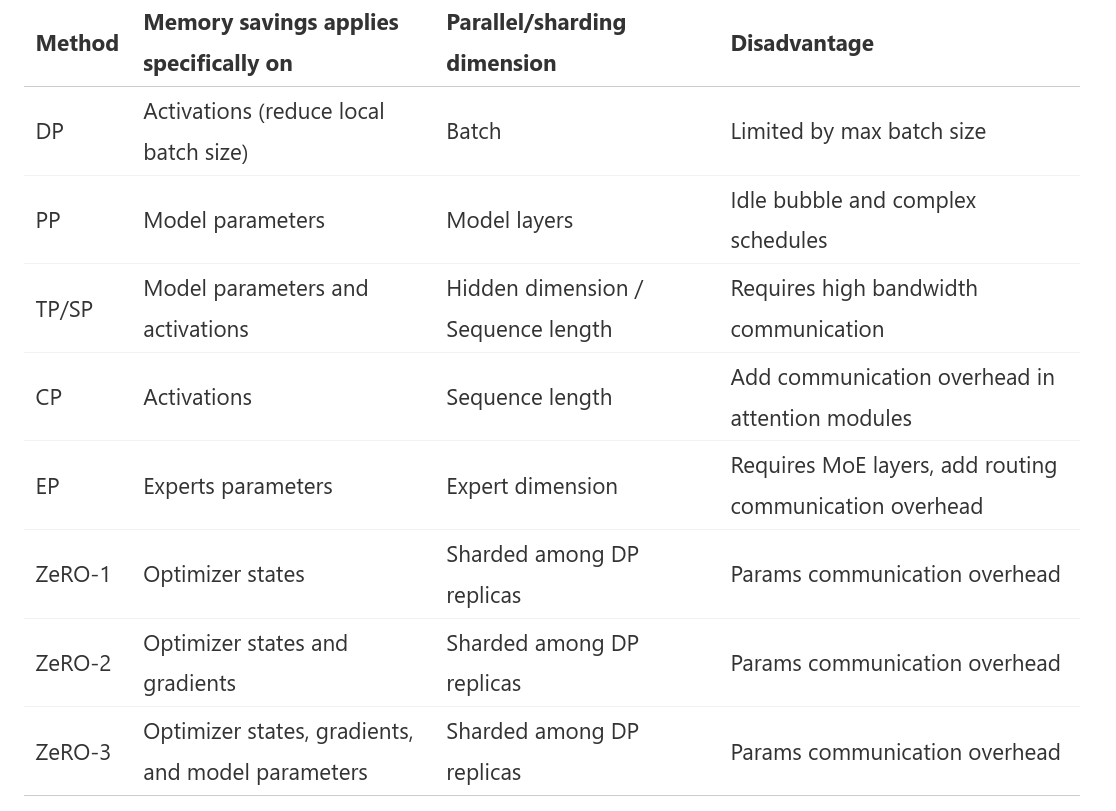
5DP
5DP自然指的就是前面提到的所有并行方案,通常情况下这五种并不完全相斥,因此对于模型结构使用合理的并行手段也是需要狠狠思考的。
比较不幸的是,我们前面介绍的两种最好用的手段:ZeRO和PP在一定程度上是互斥的(毕竟都是分隔了模型参数和中间的梯度等),因此了解两者的性能算是比较重要的一点了。

虽然都是解决模型的权重存储问题但是两者的重点不同,当然从各个角度来看,也可以通过增加batchsize来使用两种方案,但是较大的问题就是带宽也会同样变大,毕竟世界上没有免费的午餐。因此可以参考一下相关的工作,比如deepseek就采用的PP+zero-1。
解决了上述的问题之后,我们发现TP和SP是可以直接加入上述的方案的,但是是否要加入还是需要思考一下的:

对于TP而言主要有两个问题:1.其并行中间的通讯是在计算依赖中的,这种操作不可避免地会带来一定的延迟。2.这种并行需要对模型有更好的理解以及更强的编程水平以防止错误。
因此,在使用TP和SP的情况时,通常需要对节点间的网络有较高的需求。比如将通讯快的节点之间采用TP和SP而初次之外使用PP和ZeRO从而缓解带宽的限制。
对于CP和EP,两者其实处于特定场景,通常前者是面向超长token的训练场景的,毕竟在较长的token下会犹豫显存问题直接无法训练,而后者其实可以通过一定的负载均衡算法来提升性能,而且MoE也算是目前一种有效的提升模型性能的手段。


最后来一张合影假设我们已经学完了:
找到最好的配置
上述的方法虽然各有各的好处,但是毕竟没有银弹,在各种场景下仍然需要根据硬件使用对应的手段,这也是接下来要学习的内容。当然以下其实只是从理论的角度来说的。
根据钱来判断
- 情况一:我是富哥
对于小模型,我tm直接ZeRO3或者DP就能训好
对于10B~100B,使用TP=8和PP或者TP=8+ZeRO-3或者纯粹ZeRO3
对于512+显卡规模,这纯ZeRO3已经不行了,需要结合PP和ZeRO3
对于1024+显卡规模,这时候需要用TP=8 + ZeRO2+PP
对于长上下文还可以使用CP,专家模型使用EP
- 情况二:我没钱买卡
重算激活值,提高梯度积累
所以说没钱确实干不了活。
实现更高的Batch Size
DP和梯度积累,使用CP。
优化训练吞吐量
使用较高的带宽来进行较高的TP度。
使用ZeRO3,如果DP程度对通讯带宽成为瓶颈,则采用PP,具体还需要进行测试(这其实就是学术上的一种研究了)

在拥有大量的服务器进行实验的时候,或许是一个简单的问题,然而,实际上,当成千上万个配置运行时,很容易出现各种错误异常:比如pytorch清理后端不干净,部分节点出现故障,运行时间较长。因此也需要来回重启节点,合理的查看Debug目录,理解内存和CUDA内存的分配,在多节点提升PP。
上述的内容都是做PP的,接下来就是从GPU层面做优化了,这一点在CUDA中学习了很多。
结束了吗
真的结束了吗?或者说这只是一个开始,尽管接收了很多的知识,但是上述的旅程仍然是一个理论上的过程,不够详细,如果想要深刻的理解,可能动起手来才是真正消化知识的方式,接下来可以看看PicoTron和NanoTron两个项目了。