PG
当讨论到RL时,可能刻板印象还是控制游戏人机的强化学习方法:Qlearning, DQN等等。但是对于上述的强化学习策略,是根据环境所能取得的最佳策略,因此结果是确定性的,但有些实际问题需要的最优策略并不是确定性的,而是随机策略,比如石头剪刀布,如果按照一种确定性策略出拳,那么当别人抓住规律时,你就会输。所以需要引入一个新的方法去解决以上问题,比如策略梯度的方法。
RL算法依赖于actor、env和reward。其中env和reward无法控制,因此我们的做法就是通过控制actor来在env场景下获得最高的reward,这就是最基础的理解。但是问题是,在这种场景下,策略梯度的公式和优化目标如下:

其中关于参数的就不多说明了,可以看出来还是很好理解的。
但是对于强化学习而言,上述优化的目标核心是通过优化$\theta$来使得选择A更高的值,减少选择A更低的action。
这时候问题就来了:对于有真实环境场景且短视的这种on-policy的情况,用这种方式优化其实可以很轻松的满足需求。然而一旦遇到部分off-policy场景,需要设计一个值函数,同时当前的选择不一定是最好的选择的时候,就会出现很严重的问题了。
Actor-Critic
基于上述问题,实际上问题就转为了如何很好的设计这个函数使得能够取得更好跟真实的效果:

不得不说整体来说还是非常复杂的,前三个或许还是很好理解的。但是到了后面的3个就有点晕了。实际上方法4就是actor-critic的雏形——如果说我只用actor来获取值会效果不好,我可以再用一个critic模型来估计价值。所以就得到了方法4。然后在4的基础上,我们减去一个基线函数A就得到了5
关于为什么减去基准线函数,主要是由于直接使用奖励进行优化会有方差大的问题,因此使用神经网络来近似值函数并减去来减小方差使得梯度下降更加稳定
最后采用$Q=r+\gamma V$来得到方式6
Actor很好优化,但是critic应该如何优化?公式如下:

通过使得新的state状态下奖励的值提升来优化critic函数**(实际上critic指的是一个操作,其作用是根据action来获取value函数的值)**
TRPO(Trust Region Policy Optimization)
TRPO是一个基于信赖域的的策略优化算法
首先,我们知道训练的时候是为了优化policymodel使得尽可能到达一个尽可能好的效果,然而由于不稳定的梯度策略算法,每一步的训练可能会导致好或者坏,从而影响训练的稳定性。为了使得优化单调的编变好,我们可以用这个式子来优化策略模型:
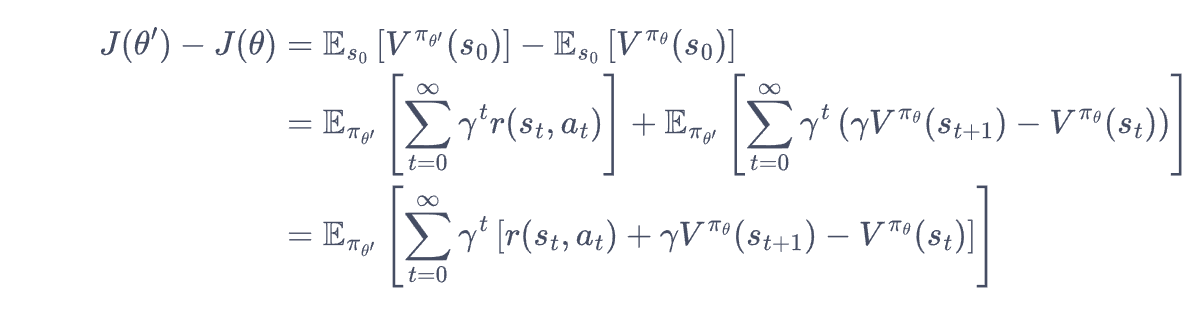
其中最后的形式其实就是前面提到的时序差分残差。省略一下其中的函数

所以实际上优化后模型和先前模型的差距就在于最后的这个优化部分,这时候问题出现了,为了优化这个式子,实际上我们是需要采用$\theta^`$模型来进行的,但是你现在还没优化到这一步,怎么得到这个模型?所以也就是接下来要解决的问题(采用近似的方式进行):

将上述的式子中的$J(\theta)$移动到右边之后,对其进行近似操作,由于在优化的时候,我们可以假设优化的时候分布的变化不大,在这种情况下我们就可以采用当前的策略近似一下未来策略。(分布的差距自然是可以用KL散度来估量的):
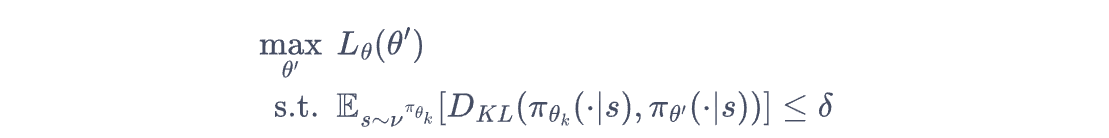
但是在凸优化的场景下,进行上述优化是一个非常复杂的问题,所以可能的方案就是:
- 泰勒逼近+KKT条件导出解
然而神经网络参数巨大,上述优化显然性能拉胯,这时候另一种手段是直接使用黑塞矩阵来优化计算,但是这种近似求解并非是朝着正向优化或者不一定满足限制所以在此基础上进行一次线性搜索确保能找到满足条件:

GAE
GAE的设计其实早就该说了,我们知道给出值函数,我们可以通过时序差分来计算优势函数,然而在实际场景中,为了得到完整流程中的优势,实际上需要对每一步都进行一个指数加权平均:

PPO(近端策略优化)
终于到PPO算法了,然而这里的PPO算法还只是强化学习中的PPO算法。PPO算法其实是在TRPO的基础上发展出来的,相较于TRPO,其主要提出了两种形式:
- PPO惩罚
- PPO裁剪
首先对于TRPO我们需要搜索一个符合限制条件的最优解,在此过程中实际上可以通过泰勒展开、共轭梯度等等方式来求解,但是即便如此,这些方法都存在计算、存储占用过大的问题。PPO就是为了设计解决这些问题的。
首先是PPO惩罚,这个可以看到,实际上这个东西就是把限制条件放到优化式子里了,就是一个拉格朗日乘数法,此时问题就变成了一个无约束的优化过程,只需要在迭代的过程中调整$\beta$即可。
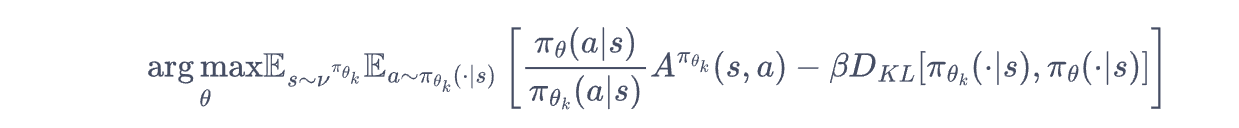
然而上述的方法还是有点复杂,更加简单粗暴的方式就是:

直接进行一个裁剪,计算差距值在一个范围内,只需要保证其差距不要太大就好,不管他好坏。
然而,上述的方法实际上都是on-policy阶段的强化学习方法,此时的环境是已知的,或者说是模型真实交互的,然而实际场景中,尤其是对于LLM场景,在使用强化学习进行优化时,我们并没有真实的环境函数用于优化,而是需要用一个专门的奖励函数来进行,这也是PPO的下半场要理解的内容了。
PPO的下半场——如何应用于LLM后训练

其实现在再看这个图就很好理解了,其中Policy Model就是要优化的模型,Reference Model是前面提到的满足约束的模型,Reward Model是奖励值函数r,Value Model是为了减少方差而设计出的深度模型。
但是还有一些细节问题需要再详细了解一下。
- Reward Model是怎么设计的?到底是一个函数还是一个模型?
RM是通过预训练模型+数据对来实现训练的。通过提供choice和reject对,来优化RM,只不过最后的LM-head换成正常的value-head来进行训练
因此RM实际上是在PPO执行之前先进行训练的
- Value Model是如何设计的
VM实际上是为了减少RM计算过程中的高方差来进行的,因此实际上参数是从RM上进行初始化的,之后在每个阶段进行Value Model的优化
-
PPO过程是怎么进行训练的
这一步得看一下源码来进行实现:
-
首先使用policy model计算所有的queries的值
-
之后对于每个大的batch计算当前policy_model的结果并计算reward值和value
-
之后在每个ppo_epoch进行优化,同时对value model和policy model进行优化
-
DPO(Direct Preference Optimization,直接偏好优化)
PPO需要使用一个奖励模型RM来监测生成效果,相较于PPO,DPO有以下好处:
- 不再训练奖励模型,直接使用人类标注的偏好数据,一步到位训练对齐模型。
- 不再使用强化学习的方法,通过数学推理,将原始的偏好对齐优化目标步步简化,最后通过类似于sft的方式,用更简化的步骤训练出对齐模型。
- 对一个问题,有两个回答 choice 和 reject,不是一个一定正确,一个一定不正确;而是训练出的语言模型,更加prefer哪一种,即希望语言模型以哪一种方式来回答。
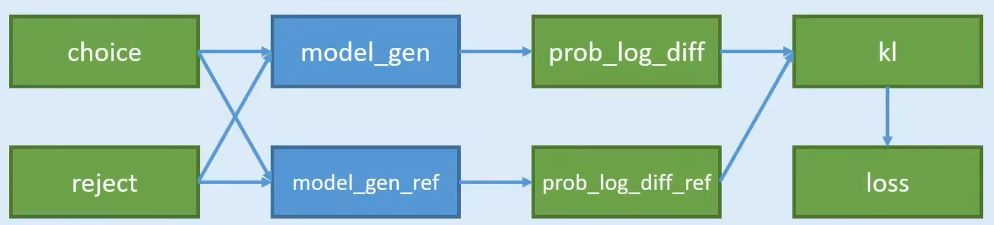
- 准备两个模型 model_gen 和 model_gen_ref,其实是一摸一样的模型,只不过在训练过程中,只会训练其中一个,另外一个是不训练的。
- 把两两份数据,分别输入到两个模型中计算,可以得到4份概率;
- 4份数据中,其中有2份是想要的,2份是不想要的;2份想要的做差,得到
pro_log_diff,2份不想要的做差pro_log_diff_ref - 拿2份做差的数据,计算KL散度;惩罚policy模型对正样本概率的下降和负样本概率的上升
- 以KL散度计算Loss
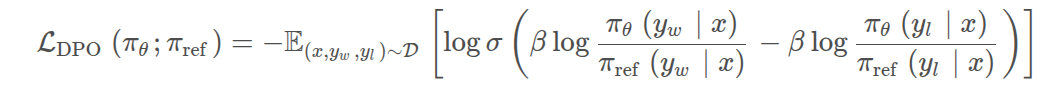
KTO
KTO从前景理论说明人类在不确定事件中做出的期望不能使期望最大化,形式化了人类对损失更加敏感。所以只需要标记好坏就好,使用起来相对来说更加简单了,首先计算参考kl散度
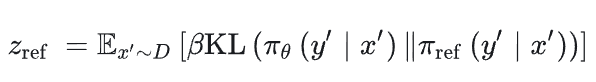
之后计算value function

然后进行加权:

最后得到损失:
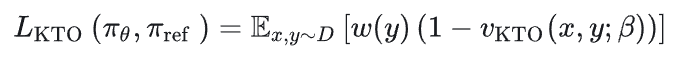
IPO
DPO算法容易在人类偏好上过拟合,所以加了一个正则化$\tau$

GRPO群体相对策略优化 (GRPO,Group Relative Policy Optimization)
https://zhuanlan.zhihu.com/p/23066650797
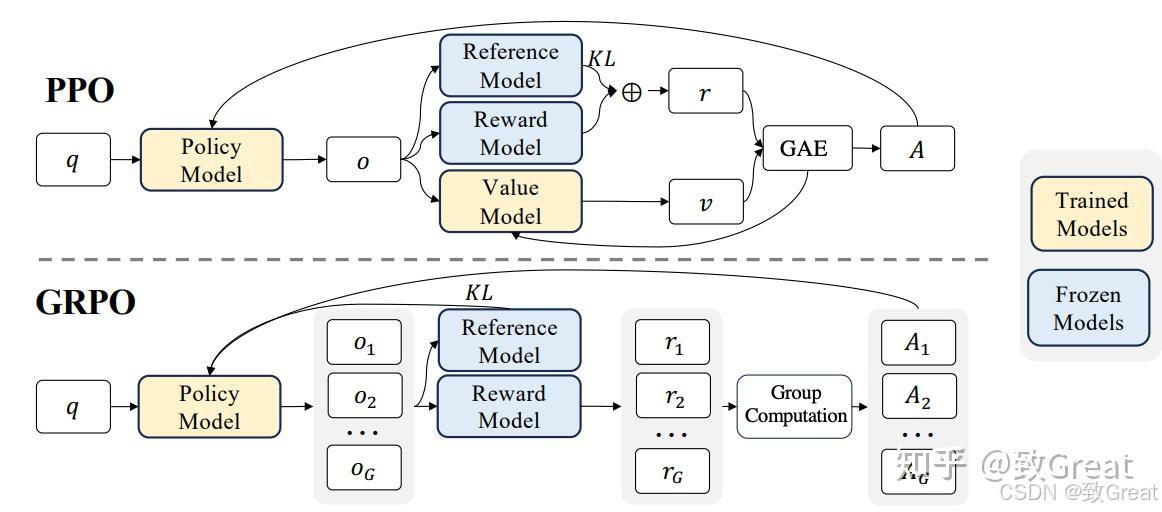
从函数来看GRPO主要由三部分组成:
- 重要性采样比 (Policy Ratio):衡量新旧策略之间的变化。
- 裁剪的目标函数 (Clipped Objective):限制策略更新幅度,以避免剧烈变化导致模型崩溃。
- KL 散度正则项 (KL Divergence Regularization):确保新策略不会偏离参考策略太远,以保持稳定性。
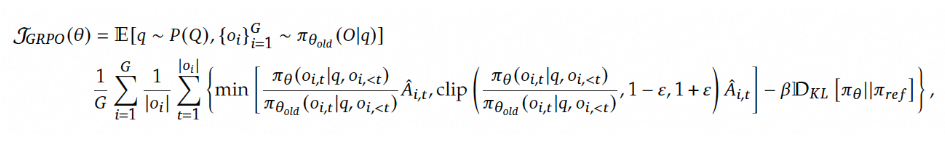
其他部分都比较好理解,其中比较重要的是优势函数的估计:
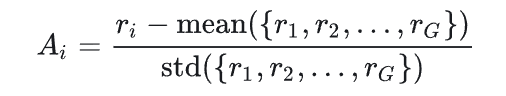
本质上就是对每个样本做正则化后求和作为优势函数。
问题就是很容易全对导致熵崩溃,且跟长度有关,会使得模型倾向于生成更长的文本。
DAPO

字节对GRPO的细节复现,主要做了如下改进:
-
裁剪偏移(Clip-Shifting),促进系统多样性并允许自适应采样;
- 采用更大范围的裁切来防止熵衰减
-
动态采样(Dynamic Sampling),提高训练效率和稳定性;
- 对采样的数据做过滤防止最后生成的数据质量接近而无法实现优化
-
Token级策略梯度损失(Token-Level Policy Gradient Loss),在长思维链 RL 场景中至关重要;
- GRPO倾向更长的token
-
溢出奖励塑造(Overflowing Reward Shaping),减少奖励噪声并稳定训练
- 根据条件截断其中的输出
-
对训练的数据格式进行了转换
DR.GRPO

删除了对长度均值以及std提升效果。
由于长上下文思考模式会显著改变模型输出分布,因此KL散度在这种场景下不必须,从而可以删除限制
KL散度三种估计

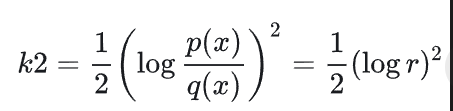
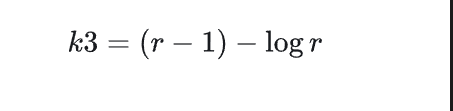
k1有偏有方差 k2有偏低方差 k3无偏低方差
其中PPO是使用KL1训练的,GRPO是使用KL3训练的