
算法
1.混淆矩阵:
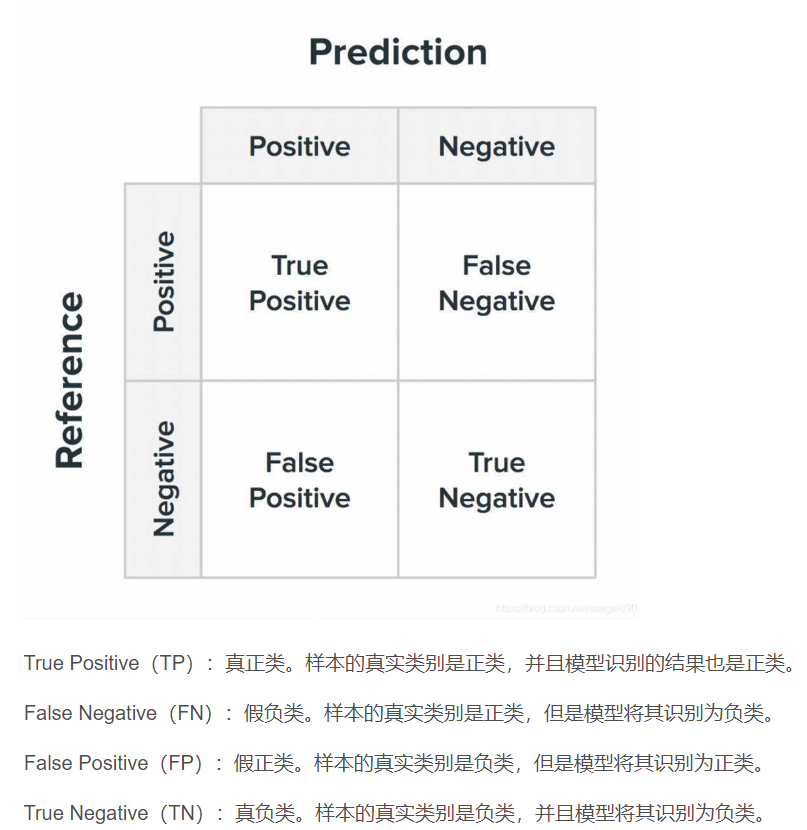
多类别的暂且不需要考虑。根据混淆矩阵可以获得多个相关的评估指标:
Precision、Recall:
$$P = \frac{TP}{TP+FP}$$
$$R = \frac{TP}{TP+FN}$$
两者是相互冲突的,可以认为P-R曲线围的越大效果越好,为了减少这种冲突的情况,还有F1度量
$$F1 = \frac{2*P*R}{P+R}$$
2.常见损失函数
评价模型的预测值和真实值不一样的程度。经验风险损失函数指预测结果和实际结果的差别,结构风险损失函数是指经验风险损失函数加上正则项。
主要有:0-1损失函数,绝对值损失函数,log对数损失函数,平方损失函数,指数损失函数,折页损失函数,感知损失函数,交叉熵损失函数(sigmoid主要使用)
https://zhuanlan.zhihu.com/p/58883095
3.常见激活函数
sigmoid(容易饱和,超过5层sigmoid就容易失去梯度) = 1 + tanh/2
https://zhuanlan.zhihu.com/p/70810466
4.常见卷积神经网络
LeNet,AlexNet,googleNet,VGG19,ResNet,MobileNet
具体的特征不说了。
5.生成模型和判别模型
判别模型已知x,y,求P(y|x)。数据要求量相较于生成模型少,不容易过拟合
生成模型估计联合概率分布,之后求出P(Y|X)作为预测的模型P(Y|X) = P(X,Y)/P(X),获得的是x和y的生成关系。可以由此得到判别模型
6.特征工程常用方法
对时间戳处理
对离散型变量进行独热编码
对连续型变量进行分箱/分区
特征缩放
特征选择
特征衍生(特征交叉)
7.常见统计学习算法
感知机模型、k近邻(主要在于快速查找)、朴素贝叶斯(生成模型)、逻辑斯蒂回归、决策树、支持向量机、boost、EM
8. Boost方法
adaboost方法:
https://zhuanlan.zhihu.com/p/38507561
9. EM方法
https://houbb.github.io/2020/01/28/math-08-em
8和9都是在思想上相当重要的方法,但是8还可以引申出更加重要的东西:stacking bagging
10. 集合学习
用多个弱学习模型来整理出来一个强大的学习模型
基于单一基础的学习算法(bagging和boosting)可以被认为是同质的
bagging独立的训练并逐渐结合,boosting用适应的方法并以此结合,stacking将异质的模型逐渐结合
说到bagging就有随机森林这个东西,可以认为一个随机森林是多个随机树组成的,但是数据可以挑选不同的或是使用不同的特征
https://towardsdatascience.com/ensemble-methods-bagging-boosting-and-stacking-c9214a10a205
11. 分类和回归问题的区别
分类解决的是离散问题而回归是一个逼近的连续问题,
python
1. os和sys的区别
os负责python与os的调用,而sys负责python与运行时的调用
2. os常用的有哪些
os用于列出目录的相关操作,或者进行os.popen进行命令行的调用,或者使用os.environ[]进行系统环境变量的配置
3. python的垃圾回收机制
引用计数(但是无法解决循环引用的问题
标记清除(用于解决循环引用
分代(用于提高gc效率
4. is和==
is是个坑,is返回的是两者的引用是否相同,==返回值相等。所以就有了这样的东西:
a, b, c, d = 1, 1, 1000, 1000
print(a is b, c is d)
def foo():
e = 1000
f = 1000
print(e is f, e is d)
g = 1
print(g is a)
foo()
True False
True False
True
前两个是因为cpython使用了small_ints缓存。此外,如果一个代码块有相同的值,优先拉取,此时两者的is相同。但是其余类型不太支持。此外pypy虽然也有类似的坑,但是在上面这个问题上,返回的全部都是True
CS224n
斯坦福大学的自然语言处理教程
Lecture 1: Introduction and Word Vectors
整体来说的话文本复杂而且在不同上下文的语义也会存在较大差异
在传统的NLP中通常有三种文本的离散化或者说编码方式:one-hot, Word2Vec, Embeddings
其中one-hot已经被时代淘汰了。Word2Vec是基于上下文实现文本的编码方式。现在常用的编码方式则是Embedding方法。one-hot自不用多说,第一节课主要讲的就是词向量的相关内容。
相较于Embedding方案,word2vec主要优化一个对数似然的过程。
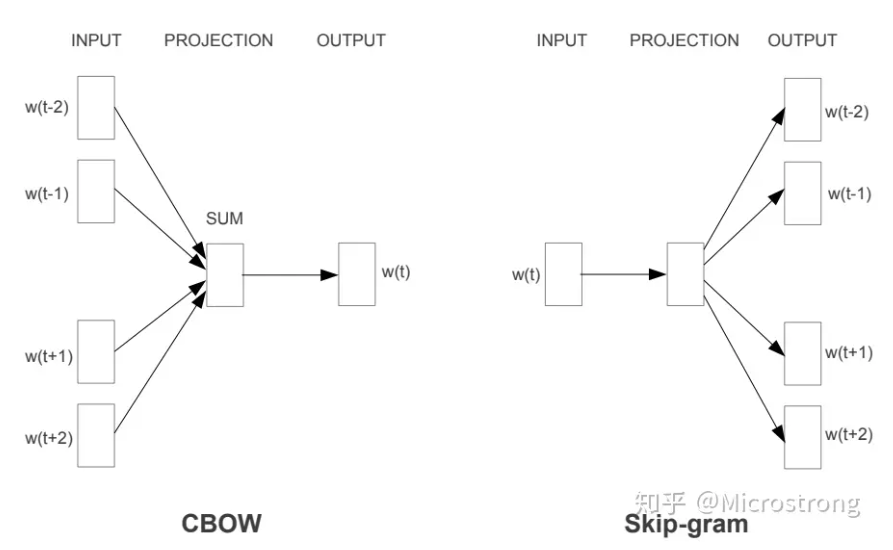
前者是CBOW的方式,通过上下文得到中间的概率,Skip-gram则与之相反。
因为文本的生成实际上可以理解成一个贝叶斯链,但是word2vec在分析的时候考虑到了上下文的相关性,因此窗口是双向的。
则整体的似然估计公式如下:
$$L(\theta)=\prod_{t=1}^T\prod_{-m\leq j\leq m,j\neq 0}P(w_{t+j}|w_t;\theta)$$
这个倒是不难理解,之后我们做一下对数和均值,就得到了损失函数:
$$J(\theta)=-\frac{1}{T}log L(\theta)$$
所以可以知道最小化损失函数可以得到最大化的预测准确率。
虽然提到了损失函数和参数$\theta$但是我们还不知道要拿来干什么(其实上图已经给出来了,是使用参数矩阵做了一个映射的操作)
现在假设每个词都有两个向量$v_w,u_w$,则我们通过如下式子计算中间词c和上下文o的似然关系:
$$P(o|c)=\frac{exp(u_o^Tv_c)}{\sum_{w\in V}exp(u_w^Tv_c)}$$
整体看上去也不复杂(但是这个东西有点意思,细心的同学应该能发下,这东西和softmax函数挺像的,但是并不是今天讨论的重点),所以只要为每个词设计两个向量,就组成了Word2Vec完整的部分(之后用快乐的梯度下降算法做一下梯度下降即可)。