开始的开始 - 策略亦有高下之分
当讨论到RL时,可能刻板印象还是控制游戏人机的强化学习方法:Qlearning, DQN等等。但是对于上述的强化学习策略,是根据环境所能取得的最佳策略,因此结果是确定性的,但有些实际问题需要的最优策略并不是确定性的,而是随机策略,比如石头剪刀布,如果按照一种确定性策略出拳,那么当别人抓住规律时,你就会输。所以需要引入一个新的方法去解决以上问题,比如策略梯度的方法。
蒙特卡罗
蒙特卡罗算法是基于采样的方法,给定策略$\pi$,让智能体与环境进行交互,就会得到很多条轨迹。 每条轨迹都有对应的回报,把每条轨迹的回报进行平均,就可以知道某一个策略下面对应状态的价值。
策略梯度算法
强化学习中有三个组成:演员(actor)、环境、奖励函数
其中环境和奖励函数不是我们可以控制的,在开始学习之前就已经事先给定。演员里会有一个策略,它用来决定演员的动作。策略就是给定一个外界输入,它会输出演员现在应该要执行的动作。唯一可以做的就是调整演员里面的策略,使得演员可以得到最大的奖励。
将深度学习与强化学习相结合时,策略ππ就是一个网络,用θθ表示ππ的参数。举上面幻境的例子,输入就是当前分身所在的分叉路口,假设可以向上,向下,向左走,经过策略网络后,输出就是三个动作可以选择的概率。然后演员就根据这个概率的分布来决定它要采取的动作,概率分布不同,演员采取的动作也不同。简单来说,策略的网络输出是一个概率分布,演员根据这个分布去做采样,决定实际上要采取的动作是哪一个。
其实PG就是蒙特卡罗与神经网络结合的算法,PG不再像Q-learning、DQN一样输出Q值,而是在一个连续区间内直接输出当前状态可以采用所有动作的概率。
结束的结束-从理论上理解就是纯纯答辩
从诸多博客看到了各色各样的花里胡哨对于算法的表示和原理,但是看到huggingface的一篇博客才知道该怎么理解。相较于从算法的角度理解,不如从直观的过程理解。
https://huggingface.co/blog/zh/rlhf
PPO算法(Proximal Policy Optimization,近端策略优化)
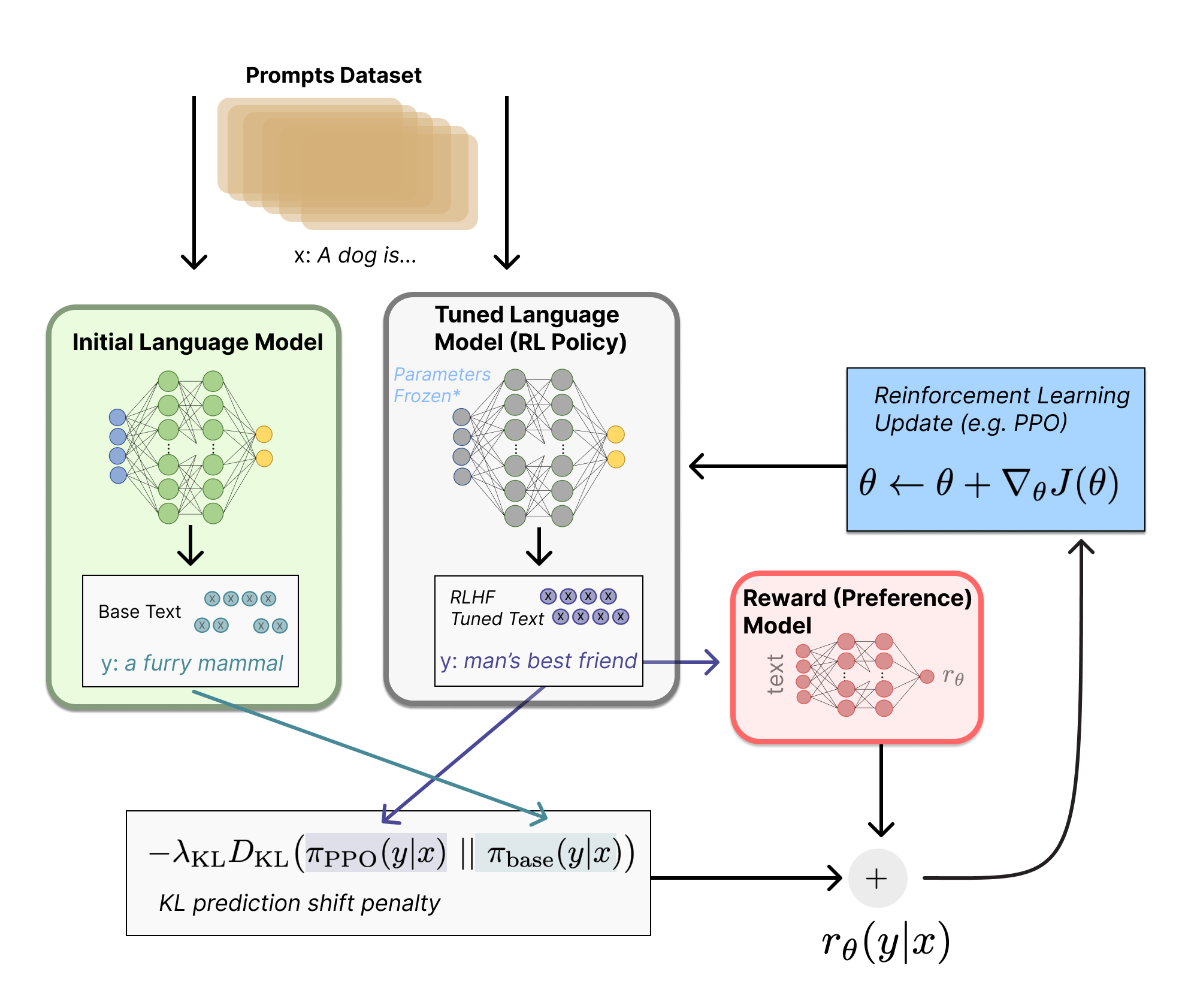
让我们首先将微调任务表述为 RL 问题。首先,该 策略 (policy) 是一个接受提示并返回一系列文本 (或文本的概率分布) 的 LM。这个策略的 行动空间 (action space) 是 LM 的词表对应的所有词元 (一般在 50k 数量级) ,观察空间 (observation space) 是可能的输入词元序列,也比较大 (词汇量 ^ 输入标记的数量) 。奖励函数 是偏好模型和策略转变约束 (Policy shift constraint) 的结合。
PPO 算法确定的奖励函数具体计算如下:将提示 x 输入初始 LM 和当前微调的 LM,分别得到了输出文本 $y1$, $y2$,将来自当前策略的文本传递给 RM 得到一个标量的奖励 $r_\theta$。将两个模型的生成文本进行比较计算差异的惩罚项,在来自 OpenAI、Anthropic 和 DeepMind 的多篇论文中设计为输出词分布序列之间的 Kullback–Leibler KL divergence散度的缩放,即 $r=r_\theta−λr_{KL}$ 。这一项被用于惩罚 RL 策略在每个训练批次中生成大幅偏离初始模型,以确保模型输出合理连贯的文本。如果去掉这一惩罚项可能导致模型在优化中生成乱码文本来愚弄奖励模型提供高奖励值。此外,OpenAI 在 InstructGPT 上实验了在 PPO 添加新的预训练梯度,可以预见到奖励函数的公式会随着 RLHF 研究的进展而继续进化。
最后根据 PPO 算法,我们按当前批次数据的奖励指标进行优化 (来自 PPO 算法 on-policy 的特性) 。PPO 算法是一种信赖域优化 (Trust Region Optimization,TRO) 算法,它使用梯度约束确保更新步骤不会破坏学习过程的稳定性。DeepMind 对 Gopher 使用了类似的奖励设置,但是使用 A2C (synchronous advantage actor-critic) 算法来优化梯度。
DPO(Direct Preference Optimization,直接偏好优化)
PPO需要使用一个奖励模型RM来监测生成效果,相较于DPO,PPO有以下好处:
- 不再训练奖励模型,直接使用人类标注的偏好数据,一步到位训练对齐模型。
- 不再使用强化学习的方法,通过数学推理,将原始的偏好对齐优化目标步步简化,最后通过类似于sft的方式,用更简化的步骤训练出对齐模型。
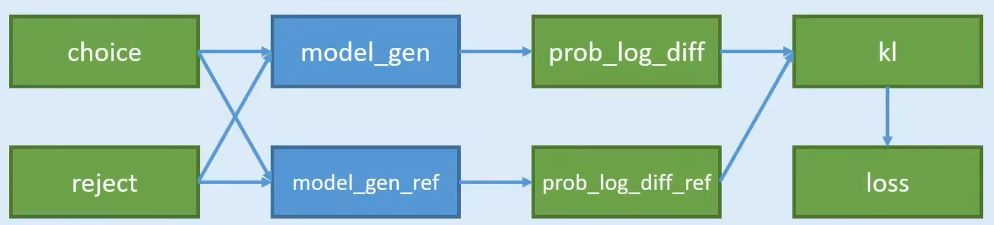
- 对一个问题,有两个回答 choice 和 reject,不是一个一定正确,一个一定不正确;而是训练出的语言模型,更加prefer哪一种,即希望语言模型以哪一种方式来回答。
- 准备两个模型 model_gen 和 model_gen_ref,其实是一摸一样的模型,只不过在训练过程中,只会训练其中一个,另外一个是不训练的。
- 把两两份数据,分别输入到两个模型中计算,可以得到4份概率;
- 4份数据中,其中有2份是想要的,2份是不想要的;2份想要的做差,得到
pro_log_diff,2份不想要的做差pro_log_diff_ref - 拿2份做差的数据,计算KL散度;惩罚policy模型对正样本概率的下降和负样本概率的上升
- 以KL散度计算Loss

GRPO群体相对策略优化 (GRPO,Group Relative Policy Optimization)
https://zhuanlan.zhihu.com/p/23066650797
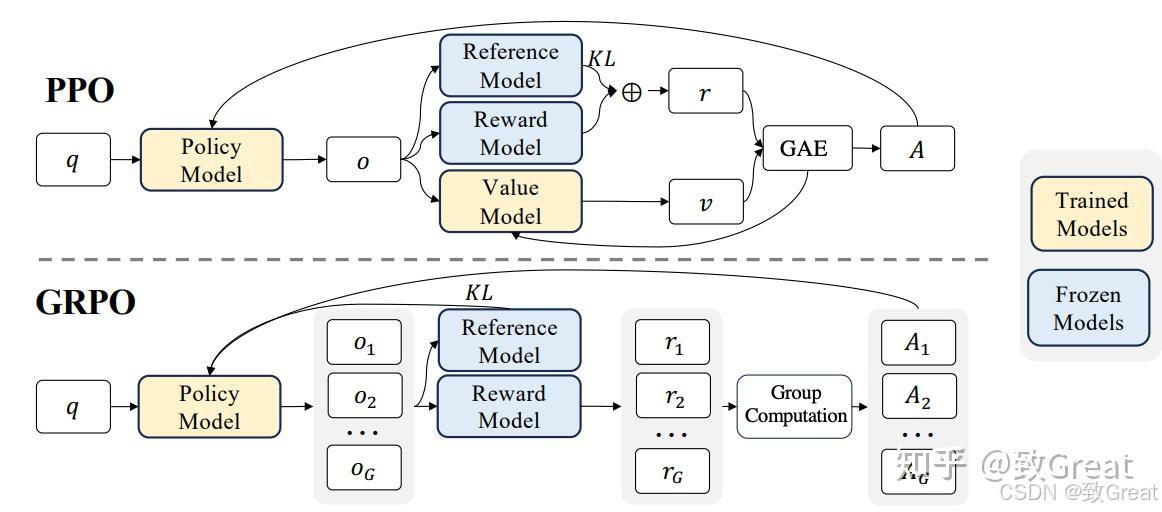
从函数来看GRPO主要由三部分组成:
- 重要性采样比 (Policy Ratio):衡量新旧策略之间的变化。
- 裁剪的目标函数 (Clipped Objective):限制策略更新幅度,以避免剧烈变化导致模型崩溃。
- KL 散度正则项 (KL Divergence Regularization):确保新策略不会偏离参考策略太远,以保持稳定性。
Yet Another PPO
https://huggingface.co/papers/2403.17031
来自于Huggingface的论文,这一篇写的更加详细清楚了。首先是基本的PPO流程,主要步骤如下:
- Step1: 对模型完成SFT步骤
- Step2: 标注来训练RM模型。将一个语言模型的头换成线性头,之后利用choice或者reject的偏好数据进行训练:

这里的$\sigma$是sigmoid函数。
- Step3:强化学习训练LLM。基于上面训练好的RM做强化学习的训练,损失如下:

其中$\beta$用来控制和原模型的相近程度。
但是上述方法的重大问题:
- 1、需要额外的数据标注训练RM模型
- 2、需要同时部署原模型、RM模型、训练中的模型,带来很大的内存需求
因此其中的一个解决手段就是采用DPO来进行优化,相较于PPO,DPO不需要额外的空间来放置RM模型,只需要获取偏好对数据并打分即可,因此对于PPO来说是相当的资源友好的。
DAPO
字节对GRPO的细节复现,主要做了如下改进:
- 裁剪偏移(Clip-Shifting),促进系统多样性并允许自适应采样;
- 采用更大范围的裁切来防止熵衰减
- 动态采样(Dynamic Sampling),提高训练效率和稳定性;
- 对采样的数据做过滤防止最后生成的数据质量接近而无法实现优化
- Token级策略梯度损失(Token-Level Policy Gradient Loss),在长思维链 RL 场景中至关重要;
- GRPO倾向更长的token
- 溢出奖励塑造(Overflowing Reward Shaping),减少奖励噪声并稳定训练
- 根据条件截断其中的输出
-
对训练的数据格式进行了转换