环境搭建
基本是一步式的了,但是可以强调一下cargo.
$ tree
.
├── .git
├── .gitignore
├── Cargo.toml
└── src
└── main.rs
运行就是:
cargo new (--bin)
cargo run
cargo build (--release)
cargo check
cargo会生成两个比较重要的文件Cargo.toml,Cargo.lock,toml是项目数据描述文件,用于添加配置项和依赖。而Cargo.lock是基于toml文件生成的依赖清单。(当项目是可运行程序时需要上传Cargo.lock否则添加到.gitignore),关于依赖可以参考:
[dependencies]
rand = "0.3"
hammer = { version = "0.5.0"}
color = { git = "https://github.com/bjz/color-rs" }
geometry = { path = "crates/geometry" }
抽象入门
rust对于没有接触过高级语言也太抽象了。
变量绑定与解构
rust与其他编程语言不同的一点在于rust的赋值更倾向是一种绑定:
let a = "hello world!";
let mut b = "hello world!!"
let _c = "";
相较于传统的默认是变量,rust这种写法得到的变量是不可变的,需要使用mut关键字。
但是即使不是mut的变量,也是可以进行修改的,这种方式叫做变量遮蔽:
fn main() {
let x = 5;
// 在main函数的作用域内对之前的x进行遮蔽
let x = x + 1;
{
// 在当前的花括号作用域内,对之前的x进行遮蔽
let x = x * 2;
println!("The value of x in the inner scope is: {}", x);
}
println!("The value of x is: {}", x);
}
运行结果非常有趣:
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
...
The value of x in the inner scope is: 12
The value of x is: 6
因为rust的变量是绑定而不是赋值,每个内存会绑定一个对应的值,第二个let实际上生成了完全不同的新变量,而在大括号的作用域内前面定义的x又被遮蔽了,所以会产生上面的效果,这种特性的好处就是在作用域内外可以使用相同的变量名称。(这跟rust的所有权息息相关)
let除了可以绑定,还可以用来解构
fn main(){
let (a, mut b) : (bool, bool) = (true, false);
println!("a = {:?}, b= {:?} ");
b = true;
assert_eq!(a, b);
}
除了使用let进行解构,也可以使用一些类似python的方法进行:
struct Struct {
e: i32
}
fn main() {
let (a, b, c, d, e);
(a, b) = (1, 2);
// _ 代表匹配一个值,但是我们不关心具体的值是什么,因此没有使用一个变量名而是使用了 _
[c, .., d, _] = [1, 2, 3, 4, 5];
Struct { e, .. } = Struct { e: 5 };
assert_eq!([1, 2, 1, 4, 5], [a, b, c, d, e]);
}
常量是不可变的,而且是全局的:
const MAX_POINTS: u32 = 100_000;
数学运算
- 数值类型: 有符号整数 (
i8,i16,i32,i64,isize)、 无符号整数 (u8,u16,u32,u64,usize) 、浮点数 (f32,f64)、以及有理数、复数 - 字符串:字符串字面量和字符串切片
&str - 布尔类型:
true和false - 字符类型: 表示单个 Unicode 字符,存储为 4 个字节
- 单元类型: 即
(),其唯一的值也是()
整数类型
要注意的内容不多,一是usize的大小视架构而定。另一点就是不检查溢出,所以需要处理溢出的情况下需要使用对应的方法:
- 使用
wrapping_*方法在所有模式下都按照补码循环溢出规则处理,例如wrapping_add - 如果使用
checked_*方法时发生溢出,则返回None值 - 使用
overflowing_*方法返回该值和一个指示是否存在溢出的布尔值 - 使用
saturating_*方法使值达到最小值或最大值
浮点数类型
要强调的只有两个:浮点数并不精确,浮点数没有实现std::cmp::Eq所以无法作为Hashmap的键。
fn main() {
let abc: (f32, f32, f32) = (0.1, 0.2, 0.3);
let xyz: (f64, f64, f64) = (0.1, 0.2, 0.3);
println!("abc (f32)");
println!(" 0.1 + 0.2: {:x}", (abc.0 + abc.1).to_bits());
println!(" 0.3: {:x}", (abc.2).to_bits());
println!();
println!("xyz (f64)");
println!(" 0.1 + 0.2: {:x}", (xyz.0 + xyz.1).to_bits());
println!(" 0.3: {:x}", (xyz.2).to_bits());
println!();
assert!(abc.0 + abc.1 == abc.2);
assert!(xyz.0 + xyz.1 == xyz.2);
}
// 虽然f64比f32更精确,但是也因此可能会出现奇怪错误,可以考虑使用(0.1_f64 + 0.2 - 0.3).abs() < 0.00001来进行比较
对于数学上未定义的结果,Rust使用NaN来处理(只有float类型有),一般可以使用is_nan()方法来判断
序列
rust使用一种非常舒服的表示来表示序列:1..5,1..=5含义倒是非常容易理解,加上循环可以类似python一样的语法:
for i in 'a'..='z' {
println!("{}",i);
}
有理数和复数
包含在num库中,需要在Cargo.toml中添加依赖
num = "0.4.0"
use num::complex::Complex;
fn main() {
let a = Complex { re: 2.1, im: -1.2 };
let b = Complex::new(11.1, 22.2);
let result = a + b;
println!("{} + {}i", result.re, result.im)
}
字符、布尔、单元
rust的字符使用的是unicode,长度为4字节。布尔型和单元型没什么好说的。
类型转换
理论上类型转换应该在数值类型之后,但是Rust的类型转换还涉及到了引用、所有权,所以暂时不急。
语句和表达式
rust需要明确的区分语句和表达式,语句是只完成一个具体的操作而不返回值,但是表达式不同,表达式会返回值
let z = {
// 分号让表达式变成了语句,因此返回的不再是表达式 `2 * x` 的值,而是语句的值 `()`
2 * x
};
函数
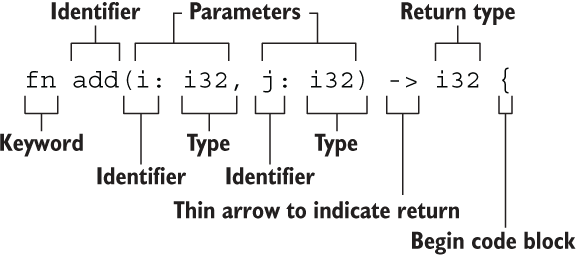
函数本身并不复杂。但是由于rust是强类型语言,因此需要明确指出参数和返回值的类型。
rust的函数有几种特殊的返回值:()空返回值。另一种是发散函数,返回值为!表示永远不返回。
字符串
字符串往往是一些语言比较基础的部分,但是对Rust来说,由于语言涉及到所有权和内存,所以使得复杂度上了一个层次:
字符串切片
很简单:
let s = String::from("hello");
let len = s.len();
let slice = &s[4..len];
let slice = &s[4..];
但是要注意的是使用切片时索引必须在字符的边界,因为对于Rust而言,字符是Unicode类型,但是字符串使用UTF-8编码,为变长编码,对于占用了三个字节的中文,就会出现崩溃的问题如何操作中文字符串:
let :&str s = "中国人";
let a = &s[0..2];
println!("{}",a);
涉及到切片的函数与借用有关系,后面会详细探讨。
Rust的字符串
从语言级别来看,Rust只有一种字符串类型str,通常以引用的形式出现&str,但实际上使用最广泛的是String类型(由存储在栈中的堆指针、字符串长度、字符串容量组成的复杂类型),因为其可变长且有所有权的字符串。
虽然str可以很方便的使用索引来获取,但是对于String就会出错,因为,String底层是以u8数组存储的,对于UTF-8编码的字符串,不同字符串占用的大小不同,对于索引会有很大的困难,所以不具有索引类型,同时也因为这个特性不能对字符串进行切片,所以一般需要使用引用类型转换为&str后进行操作。
但是字符串类型可以实现很多例如追加、插入、删除、替换的操作,这里使用一些例子:
fn main() {
let mut s = String::from("Hello ");
s.push_str("rust");
println!("追加字符串 push_str() -> {}", s);
s.push('!');
println!("追加字符 push() -> {}", s);
}
fn main() {
let mut s = String::from("Hello rust!");
s.insert(5, ',');
println!("插入字符 insert() -> {}", s);
s.insert_str(6, " I like");
println!("插入字符串 insert_str() -> {}", s);
}
fn main() {
let string_replace = String::from("I like rust. Learning rust is my favorite!");
let new_string_replace = string_replace.replace("rust", "RUST");
dbg!(new_string_replace);
}
fn main() {
let mut string_pop = String::from("rust pop 中文!");
let p1 = string_pop.pop();
let p2 = string_pop.pop();
dbg!(p1);
dbg!(p2);
dbg!(string_pop);
}
fn main() {
let mut string_remove = String::from("测试remove方法");
println!(
"string_remove 占 {} 个字节",
std::mem::size_of_val(string_remove.as_str())
);
// 删除第一个汉字
string_remove.remove(0);
// 下面代码会发生错误
// string_remove.remove(1);
// 直接删除第二个汉字
// string_remove.remove(3);
dbg!(string_remove);
}
fn main() {
let mut string_clear = String::from("string clear");
string_clear.clear();
dbg!(string_clear);
}
fn main() {
let string_append = String::from("hello ");
let string_rust = String::from("rust");
// &string_rust会自动解引用为&str
// fn add(self, s: &str) -> String
let result = string_append + &string_rust;
let mut result = result + "!"; // `result + "!"` 中的 `result` 是不可变的
result += "!!!";
println!("连接字符串 + -> {}", result);
}
fn main() {
let s1 = String::from("hello,");
let s2 = String::from("world!");
// 在下句中,s1的所有权被转移走了,因此后面不能再使用s1(因为add(方法把s1的所有权借走了,所以s1不存在了))
let s3 = s1 + &s2;
assert_eq!(s3,"hello,world!");
// 下面的语句如果去掉注释,就会报错
// println!("{}",s1);
}
for c in "中国人".chars() {
println!("{}", c);
}
但是为什么String可变而str不可变?由于str属于字符串自变量,在编译时需要硬编码到可执行文件中,使得快速且高效,坏处就是不可变,而String是为了支持一个可变增长的文本片段,需要分配,这是程序运行时完成的。
同时由于Rust没有使用GC机制,当变量脱离定义域时将会自动被清理内存,从而减少了编码和维护成本。
所有权和借用
传统的内存安全都是通过GC的方式实现,但是往往会带来性能、内存占用上的问题,所以在高性能场景和系统编程中无法被接受,所以Rust实现了所有权系统。这就是Rust第一个最难的地方。
在处理计算机内存的过程中,逐渐出现了三种流派:
- 垃圾回收GC(如Go、java)
- 手动管理(C++、C)
- 所有权
其中所有权的好处就是只有在编译期做了检查,所以性能较高。
堆和栈通常是常用的数据结构,但是对于理解rust的存储非常重要。核心可以用几点表示一下:栈快,堆慢。栈整齐堆没有组织。
当进行函数调用时,参数被依次压入栈中,函数调用结束时按顺序移除,但是由于堆上组织不到位,所以挺容易出现函数结束内存没有被很好清理的结果,从而导致内存泄漏。
Rust的所有权原则如下:
- Rust 中每一个值都被一个变量所拥有,该变量被称为值的所有者
- 一个值同时只能被一个变量所拥有,或者说一个值只能拥有一个所有者
- 当所有者(变量)离开作用域范围时,这个值将被丢弃(drop)
就变量的作用域而言,其与其他语言相同。由于一个值只能有一个所有者,所以当变量被另一个变量赋值时,既不是深拷贝、也不是浅拷贝,而是进行了一次所有权的转移:
let s1 = String::from("hello");
let s2 = s1;
println!("{}, world!", s1);
上述代码会提示s1为无效的引用,这就是由于所有权被转移而导致的。另一个对应的例子:
let x = 5;
let y = x;
println!("x = {}, y = {}", x, y);
上述代码同样类似所有权的转移,但是却没有报错,这里涉及到rust的拷贝问题了。由于基本类型在编译时是已知大小的,会被存储在栈上,所以实现了类似”深拷贝“的“浅拷贝”。
拷贝
虽然rust使用了所有权转移的概念,但是拷贝还是必不可缺的。rust的拷贝同样分为深拷贝和浅拷贝。深拷贝需要调用.clone()方法进行深拷贝。
浅拷贝的概念自不必说,但是在rust中,如何确认什么时候是浅拷贝什么时候是深拷贝?这里有一个通用规则(需要实现Copy特征):任何基本类型的组合可以 Copy ,不需要分配内存或某种形式资源的类型是可以 Copy 的
函数传值与返回
值传给函数可以理解成调用了let方法。
fn main() {
let s = String::from("hello"); // s 进入作用域
takes_ownership(s); // s 的值移动到函数里 ...
// ... 所以到这里不再有效
let x = 5; // x 进入作用域
makes_copy(x); // x 应该移动函数里,
// 但 i32 是 Copy 的,所以在后面可继续使用 x
} // 这里, x 先移出了作用域,然后是 s。但因为 s 的值已被移走,
// 所以不会有特殊操作
fn takes_ownership(some_string: String) { // some_string 进入作用域
println!("{}", some_string);
} // 这里,some_string 移出作用域并调用 `drop` 方法。占用的内存被释放
fn makes_copy(some_integer: i32) { // some_integer 进入作用域
println!("{}", some_integer);
} // 这里,some_integer 移出作用域。不会有特殊操作
相当安全,但是代价就是参数得传来传去………吗?实际上rust解决了这个问题。
引用与借用
如果只是使用所有权转移的话,可能连多个返回值都很难做到,所有rust还使用了借用和引用概念
rust支持类似C++,C的引用,同时添加了借用的概念:获取变量的引用,称之为借用(borrowing)
引用和借用的使用倒是一点都不复杂:
fn main() {
let x = 5;
let y = &x;
assert_eq!(5, x);
assert_eq!(5, *y);
}
rust的引用类似C++和C,因此也没什么多说的,但是默认的引用是不可变引用,所以无法在函数中修改引用的值:
fn main() {
let s = String::from("hello");
change(&s);
}
fn change(some_string: &String) {
some_string.push_str(", world");
}
会报错,但是修改方式也很容易:
fn main() {
let mut s = String::from("hello");
change(&mut s);
}
fn change(some_string: &mut String) {
some_string.push_str(", world");
}
注意三个重要的地方:声明可变类型、创建可变引用、接受可变引用参数的函数。
但是rust会有大坑!有两个限制条件:
1、同一作用域,特定数据只能有一个可变引用:
let mut s = String::from("hello");
let r1 = &mut s;
let r2 = &mut s;
println!("{}, {}", r1, r2);
这是为了避免rust在编译时避免数据竞争
2、可变引用与不可变引用不能同时存在
let mut s = String::from("hello");
let r1 = &s; // 没问题
let r2 = &s; // 没问题
let r3 = &mut s; // 大问题
println!("{}, {}, and {}", r1, r2, r3);
这是为了防止变量污染
同时要注意不同版本的编译器的作用域控制不同。
fn main() {
let mut s = String::from("hello");
let r1 = &s;
let r2 = &s;
println!("{} and {}", r1, r2);
// 新编译器中,r1,r2作用域在这里结束
let r3 = &mut s;
println!("{}", r3);
} // 老编译器中,r1、r2、r3作用域在这里结束
// 新编译器中,r3作用域在这里结束
新版本的编译器可以找到最后一次使用的位置。称之为Non-Lexical Lifetimes。
悬垂引用
fn main() {
let reference_to_nothing = dangle();
}
fn dangle() -> &String {
let s = String::from("hello");
&s
}
类似C++和C。
所以借用规则整体来说也很简单:
- 同一时刻,你只能拥有要么一个可变引用, 要么任意多个不可变引用
- 引用必须总是有效的